
tagged by: data analytics
Data Mesh Principles and Logical Architecture
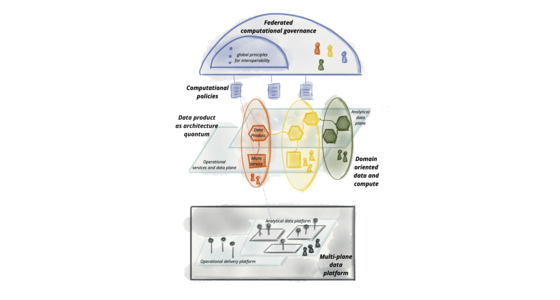
Our aspiration to augment and improve every aspect of business and life with data, demands a paradigm shift in how we manage data at scale. While the technology advances of the past decade have addressed the scale of volume of data and data processing compute, they have failed to address scale in other dimensions: changes in the data landscape, proliferation of sources of data, diversity of data use cases and users, and speed of response to change. Data mesh addresses these dimensions, founded in four principles: domain-oriented decentralized data ownership and architecture, data as a product, self-serve data infrastructure as a platform, and federated computational governance. Each principle drives a new logical view of the technical architecture and organizational structure.
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
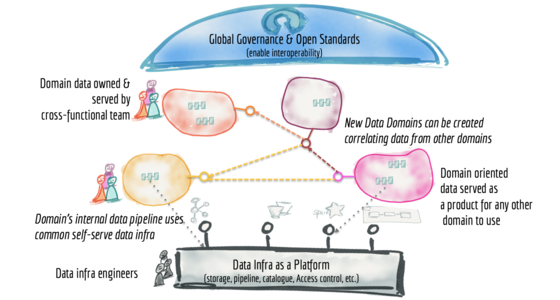
Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
Don't Compare Averages
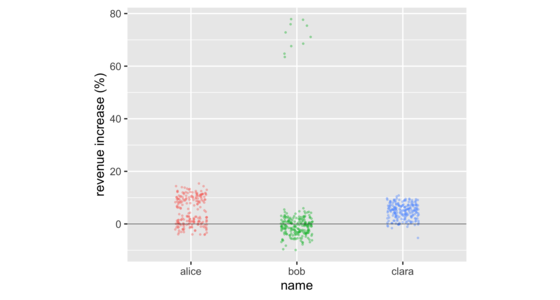
In business meetings, it's common to compare groups of numbers by comparing their averages. But doing so often hides important information in the distribution of the numbers in those groups. There are a number of data visualizations that shine a light on this information. These include strip charts, histograms, density plots, box plots, and violin plots. These are easy to produce with freely available software, working on groups as small as a dozen, or as large as thousands.
Privacy Enhancing Technologies: An Introduction for Technologists
Privacy Enhancing Technologies (PETs) are technologies that provide increased privacy or secrecy for the persons whose data is processed, stored and/or collected by software and systems. Three PETs that are valuable and ready for use are: Differential Privacy, Distributed & Federated Analysis & Learning, and Encrypted Computation. They provide rigorous guarantees for privacy and as such are becoming increasingly popular to provide data in while minimizing violations of private data.
Continuous Delivery for Machine Learning
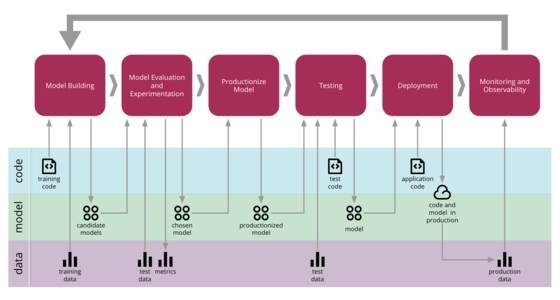
Machine Learning applications are becoming popular in our industry, however the process for developing, deploying, and continuously improving them is more complex compared to more traditional software, such as a web service or a mobile application. They are subject to change in three axis: the code itself, the model, and the data. Their behaviour is often complex and hard to predict, and they are harder to test, harder to explain, and harder to improve. Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications.
Bitemporal History
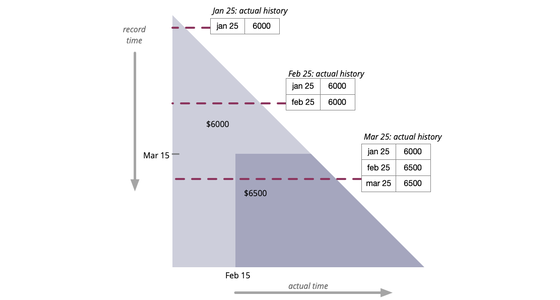
It's often necessary to access the historical values of some property. But sometimes this history itself needs to be modified in response to retroactive updates. Bitemporal history treats time as two dimensions: actual history records what history should be given perfect transmission of information, while record history captures how our knowledge of history changes.
Data Mesh Accelerate Workshop

To accelerate means to move faster, to gain speed. Effectively working with data is key for any organization that wants to thrive in the modern world, and Data Mesh is showing organizations how to realise value from their data, at scale. The Data Mesh Accelerate workshop helps teams and organisations accelerate their Data Mesh transformation, by understanding their current state and exploring what the next steps will look like.
Don't put data science notebooks into production
We've come across many clients who are interested in taking the computational notebooks developed by their data scientists, and putting them directly into the codebase of production applications. Data science ideas do need to move out of notebooks and into production, but trying to deploy that notebooks as a code artifact breaks a multitude of good software practices. Predictably, that results in a number of observed pain points. This behavior is a symptom of a deeper problem: a lack of collaboration between data scientists and software developers.
The Evolving Panorama of Data
Our keynote at QCon London 2012 looks at the role data is playing in our lives (and that it's doing more than just getting bigger). We start by looking at how the world of data is changing: its growing, becoming more distributed and connected. We then move to the industry's response: the rise of NoSQL, the shift to service integration, the appearance of event sourcing, the impact of clouds and new analytics with a greater role for visualization. We take a quick look at how data is being used now, with a particular emphasis from Rebecca on data in the developing world. Finally we consider what does all this mean to our personal responsibilities as software professionals.
Thinking about Big Data
“Big Data” has leapt rapidly into one of the most hyped terms in our industry, yet the hype should not blind people to the fact that this is a genuinely important shift about the role of data in the world. The amount, speed, and value of data sources is rapidly increasing. Data management has to change in five broad areas: extraction of data from a wider range of sources, changes to the logistics of data management with new database and integration approaches, the use of agile principles in running analytics projects, an emphasis on techniques for data interpretation to separate signal from noise, and the importance of well-designed visualization to make that signal more comprehensible. Summing up this means we don't need big analytics projects, instead we want the new data thinking to permeate our regular work.
A Proof-of-Concept of BigQuery
Can Google’s new BigQuery service give customers Big Data analytic power without the need for expensive software or new infrastructure? Thoughtworks and AutoTrader conducted a weeklong proof of concept test, using a massive data set. The tests showed consistent query performance on a 750 million row data set in the 7-10 second range. We used the REST APIs with Java, JavaScript and Google Charts to create a web front-end with interactive visuals of query results. The entire exercise was conducted with three people in five days. The verdict: BigQuery performed well, and could benefit organisations with Big Data and smaller budgets—especially those without a data warehouse, or whose data warehouse has restricted use.
Introduction to NoSQL

At goto Aarhus, we had a track on some practical experiences with NoSQL. I was asked to give an initial talk to explain the basic principles of NoSQL datastores. I talk about the origins of NoSQL, forms of NoSQL data models, the way many NoSQL databases consider the problem of consistency, and the importance of Polyglot Persistence.
Engineering Room Conversation with Dave Farley
My old colleague Dave Farley has been running an increasingly popular YouTube channel on software development. It's good material, very much in line with my own views, after all his experience is a big influence on my thinking. We talk about a range of topics about the current role of software engineering, focusing particularly on the three large-scale writing projects I'm supporting at the moment: Data Mesh, Patterns of Distributed Systems, and Patterns of Legacy Displacement.
The Evolving Role of Data in Software Development
Unable to travel to Australia for their 2020 XConf, I instead had a zoom conversation with Scott Shaw: Thoughtworks Head of Technology for Australia. We talked about the changing role data plays in modern application development: the divide between application developers and databases, the changes due to the appearance of big (and messy) data, the need to improve data literacy, and the societal impact of hoovering up speculative data.
It's Different with Data
Em Grasmeder, our European “Data Witch”, and I had planned to keynote our XConf series in Europe. Being 2020, instead we Zoomed, and talked about the role of data scientists: what the role actually is, the tools they need to acquire, and their relationship with other forms of software development.
Muted spaghetti line charts with R's ggplot2
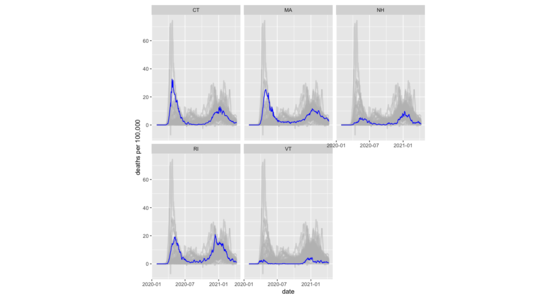
How I plot a muted-spaghetti chart with R, including facets.
Communal Dashboard

With the growing interest in data analytics and visualizations, we're seeing more effort put into interesting visualizations that allow people to draw insight from data floating around in an organization. Most of these dashboards are aimed at individual usage, but there is a growing tendency to use them for a more communal purpose.
Computational Notebook
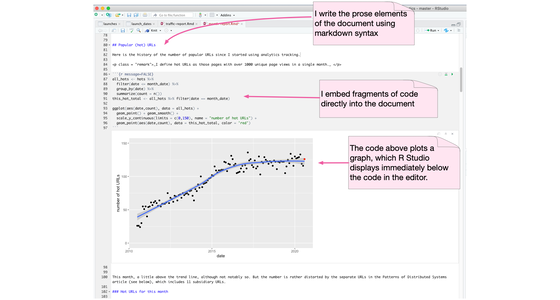
A computational notebook is an environment for writing a prose document that allows the author to embed code which can be easily executed with the results also incorporated into the document. It's a platform particularly well-suited for data science work. Such environments include Jupyter Notebook, R Markdown, Mathematica, and Emacs's org-mode.
Data Lake
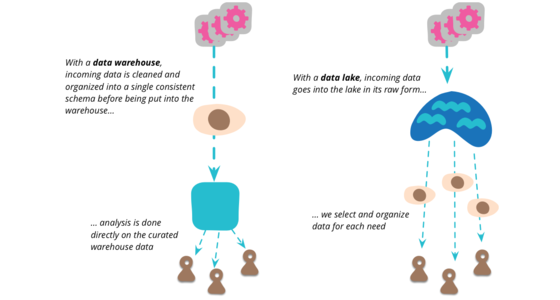
Data Lake is a term that's appeared in this decade to describe an important component of the data analytics pipeline in the world of Big Data. The idea is to have a single store for all of the raw data that anyone in an organization might need to analyze. Commonly people use Hadoop to work on the data in the lake, but the concept is broader than just Hadoop.
Datensparsamkeit
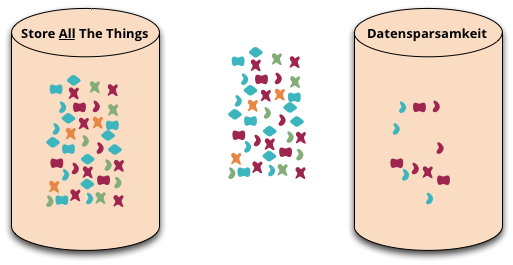
Datensparsamkeit is a German word that's difficult to translate properly into English. It's an attitude to how we capture and store data, saying that we should only handle data that we really need.
Machine Justification
I remember in my teens being told of the wonderful things Artificial Intelligence (AI) would do in the next few years. Now several decades later, some of these seem to be happening. The most recent triumph was of computers teaching each other to play Go by playing against each other, rapidly becoming more proficient than any human, with strategies human experts could barely comprehend. It's natural to wonder what will happen over the next few years, will computers soon have greater intelligence than humanity? (Given some recent election results, that may not be too hard a bar to cross.)
But as I hear of these, I recall Pablo Picasso's comment about computers many decades ago: “Computers are useless. They can only give you answers”. The kind of reasoning that techniques such as Machine Learning can result in are truly impressive in their results, and will be useful to us as users and developers of software. But answers, while useful, aren't always the whole picture. I learned this in my early days of school - just providing the answer to a math problem would only get me a couple of marks, to get the full score I had to show how I got it. The reasoning that got to the answer was more valuable than the result itself. That's one of the limitations of the self-taught Go AIs. While they can win, they cannot explain their strategies.
Probabilistic Illiteracy
As I write this towards the conclusion of the US presidential election , there's a side debate that's appeared about the forecasts produced by Nate Silver. Many Republicans claim he's a shill for the democrats and his forecast of an 85% chance of an Obama win is bogus . Part of me wishes I knew more innumerate Republicans that I could make side-bets with. Perhaps a better wish would be that the polls were the other way around as I have more Democratic-leaning friends. In reality either way I wouldn't gain too much as most people I know are numerate. Sadly this isn't true in general - this side-show is an illustration of the deep illiteracy most people have for probability, which has some important ramifications for society in general and software development in particular.