
tagged by: database
Evolutionary Database Design
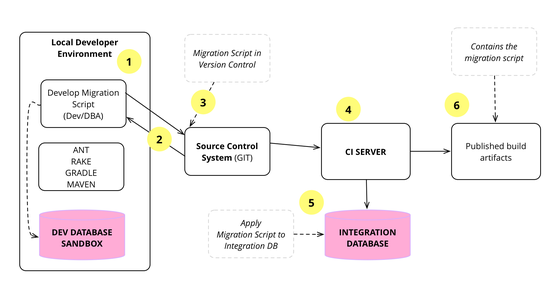
Over the last decade we've developed and refined a number of techniques that allow a database design to evolve as an application develops. This is a very important capability for agile methodologies. The techniques rely on applying continuous integration and automated refactoring to database development, together with a close collaboration between DBAs and application developers. The techniques work in both pre-production and released systems, in green field projects as well as legacy systems.
Hexagonal Architecture and Rails
A couple of videos of a conversation between me and my colleague Badri about hexagonal architecture and its role in a Rails application. In the first video we talk about what Hexagonal Architecture means and how this leads into the choice between the Active Record and Data Mapper patterns for a persistance framework. In the second we move more broadly into the architectural role Rails should play in an application - should you see it as a platform, or a suite of components.
The Evolving Panorama of Data
Our keynote at QCon London 2012 looks at the role data is playing in our lives (and that it's doing more than just getting bigger). We start by looking at how the world of data is changing: its growing, becoming more distributed and connected. We then move to the industry's response: the rise of NoSQL, the shift to service integration, the appearance of event sourcing, the impact of clouds and new analytics with a greater role for visualization. We take a quick look at how data is being used now, with a particular emphasis from Rebecca on data in the developing world. Finally we consider what does all this mean to our personal responsibilities as software professionals.
Introduction to NoSQL

At goto Aarhus, we had a track on some practical experiences with NoSQL. I was asked to give an initial talk to explain the basic principles of NoSQL datastores. I talk about the origins of NoSQL, forms of NoSQL data models, the way many NoSQL databases consider the problem of consistency, and the importance of Polyglot Persistence.
Schemaless Data Structures

In recent years, there's been an increasing amount of talk about the advantages of schemaless data. Being schemaless is one of the main reasons for interest in NoSQL databases. But there are many subtleties involved in schemalessness, both with respect to databases and in-memory data structures. These subtleties are present both in the meaning of schemaless and in the advantages and disadvantages of using a schemaless approach.
SE Radio Podcast on Agile Database Development
Pramod Sadalge led the development of agile database techniques which we now use habitually at Thoughtworks. SE Radio interviews us about how we use these techniques to evolve the design of a database iteratively together with applications that use it. We discuss how to incorporate databases into a Continuous Integration system, how to make database changes through repeatable scripted migrations, and how database refactoring works.
The Future is not NoSQL but Polyglot Persistence
An infodeck on the future of data storage in the enterprise, written primarily for those involved in the management of application development. Explains why relational databases have been the dominant, why NoSQL is challenging this assumption and sketches out the future of Polyglot Persistence, where multiple data storage technologies will be used for applications depending on their varied needs.
Domain Logic and SQL
Over the last couple of decades we've seen a growing gap between database-oriented software developers and in-memory application software developers. This leads to many disputes about how to use database features such as SQL and stored procedures. In this article I look at the question of whether to place business logic in SQL queries or in-memory code, considering primarily performance and maintainability based on an example of a simple, but rich SQL query.
Aggregate Oriented Database
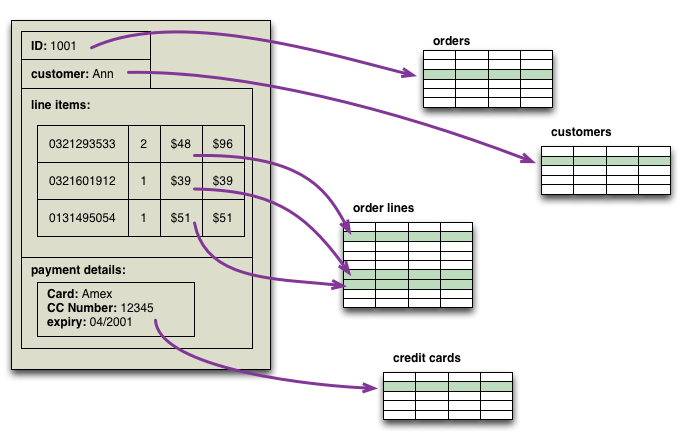
One of the first topics to spring to mind as we worked on Nosql Distilled was that NoSQL databases use different data models than the relational model. Most sources I've looked at mention at least four groups of data model: key-value, document, column-family, and graph. Looking at this list, there's a big similarity between the first three - all have a fundamental unit of storage which is a rich structure of closely related data: for key-value stores it's the value, for document stores it's the document, and for column-family stores it's the column family. In DDD terms, this group of data is an DDD_Aggregate.
Application Database
I use the term Application Database for a database that is controlled and accessed by a single application, (in contrast to an IntegrationDatabase). Since only a single application accesses the database, the database can be defined specifically to make that one application's needs easy to satisfy. This leads to a more concrete schema that is usually easier to understand and often less complex than that for an IntegrationDatabase.
Data Lake
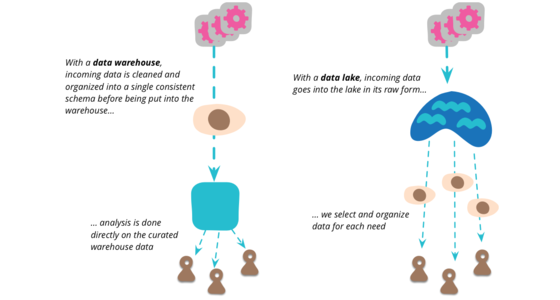
Data Lake is a term that's appeared in this decade to describe an important component of the data analytics pipeline in the world of Big Data. The idea is to have a single store for all of the raw data that anyone in an organization might need to analyze. Commonly people use Hadoop to work on the data in the lake, but the concept is broader than just Hadoop.
Data Models
One of my early favorite books was Tsichritzis and Lochovsky's book on Data Models. The book discussed different models for thinking about data, in particular the three models most discussed at the time: RelationalDataModel, HierarchicDataModel and NetworkDataModel.
Database Styles
When I talk about databases and how they relate to applications, I've found it useful to distinguish between two styles of database: ApplicationDatabase and IntegrationDatabase. The difference between the two lies in whether the database is controlled and encapsulated within a single ApplicationBoundary.
Database Thaw
A few years ago I heard programming language people talk about the “Nuclear Winter” in languages caused by Java. The feeling was that everyone had so converged on Java's computational model (C# at that point seen as little more than a rip-off) that creativity in programming languages had disappeared. That feeling is now abating, but perhaps a more important thaw that might be beginning - the longer and deeper freeze in thinking about databases.
Datensparsamkeit
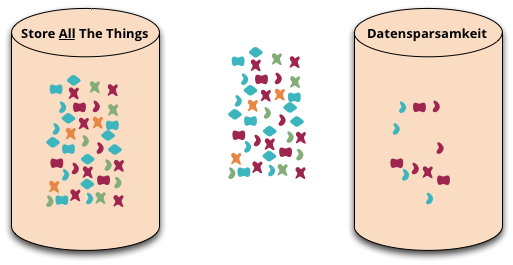
Datensparsamkeit is a German word that's difficult to translate properly into English. It's an attitude to how we capture and store data, saying that we should only handle data that we really need.
Hierarchic Data Model
A hierarchic data model organizes in the form of a hierarchy or tree structure. Early databases and programming data structures commonly used hierarchic models, but these fell out of favor. In the database world the RelationalDataModel became dominant, while for most in-memory programming the NetworkDataModel dominates. This was due to the fact that a hierarchy, while a simple organizational tool, breaks down as you get more complex data.
In Memory Test Database
An in-memory database is a database that runs entirely in main memory, without touching a disk. Often they run as an embedded database: created when a process starts, running embedded within that process, and is destroyed when the process finishes.
Incremental Migration
Like any profession, software development has it's share of oft-forgotten activities that are usually ignored but have a habit of biting back at just the wrong moment. One of these is data migration.
Integration Database
An integration database is a database which acts as the data store for multiple applications, and thus integrates data across these applications (in contrast to an ApplicationDatabase).
Memory Image
When people start an enterprise application, one of the earliest questions is “how do we talk to the database”. These days they may ask a slightly different question “what kind of database should we use - relational or one of these NOSQL databases?”. But there's another question to consider: “should we use a database at all?”
Network Data Model
The network data model structures data as record types, with pointer links to allow to navigate between one record and another. So to query a network data model you begin at one record and move around pointer references.
No DBA

In many organizations, it's expected that any persistent data will be stored in relational databases that are managed by a central database management group. There are various reasons for such central control, usually centered around using IntegrationDatabases. Central data groups worry about keeping out malformed data, queries that can slow down important shared resources, and consistent data models across the enterprise.
Worthy these aims may be, but one consequence of them is considerable ceremony about storing data. I often hear complaints about change orders that take weeks to add a column to a database. For modern application developers, used to short-cycle evolutionary design, such ceremony is too slow, not to mention too annoying.
So application development groups tell me of using NoSQL databases to do an end-run around the DBAs. It helps that they are using a “mere datastore” here, not a “proper database”. That way the DBAs can be kept out of the loop, often not told or happy to not care.
Nosql Definition
As soon as we started work on Nosql Distilled we were faced with a tricky conundrum - what are we writing about? What exactly is a NoSQL database? There's no strong definition of the concept out there, no trademarks, no standard group, not even a manifesto.
Orm Hate
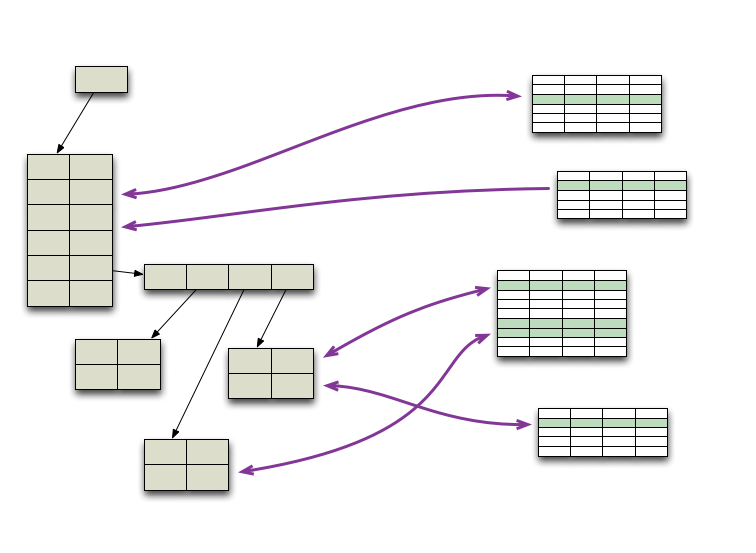
While I was at the QCon conference in London a couple of months ago, it seemed that every talk included some snarky remarks about Object/Relational mapping (ORM) tools. I guess I should read the conference emails sent to speakers more carefully, doubtless there was something in there telling us all to heap scorn upon ORMs at least once every 45 minutes. But as you can tell, I want to push back a bit against this ORM hate - because I think a lot of it is unwarranted.
Polyglot Persistence
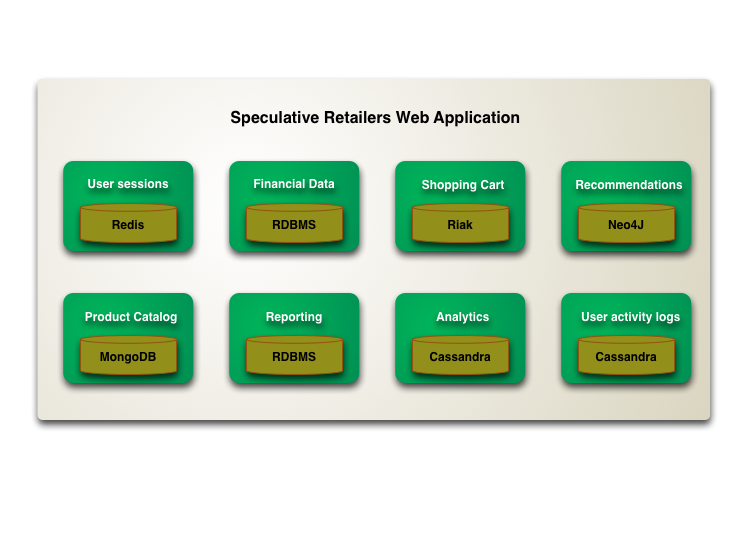
In 2006, my colleague Neal Ford coined the term Polyglot Programming, to express the idea that applications should be written in a mix of languages to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for the job may be more productive than trying to fit all aspects into a single language.
Over the last few years there's been an explosion of interest in new languages, particularly functional languages, and I'm often tempted to spend some time delving into Clojure, Scala, Erlang, or the like. But my time is limited and I'm giving a higher priority to another, more significant shift, that of the DatabaseThaw. The first drips have been coming through from clients and other contacts and the prospects are enticing. I'm confident to say that if you starting a new strategic enterprise application you should no longer be assuming that your persistence should be relational. The relational option might be the right one - but you should seriously look at other alternatives.
Presentation Domain Data Layering
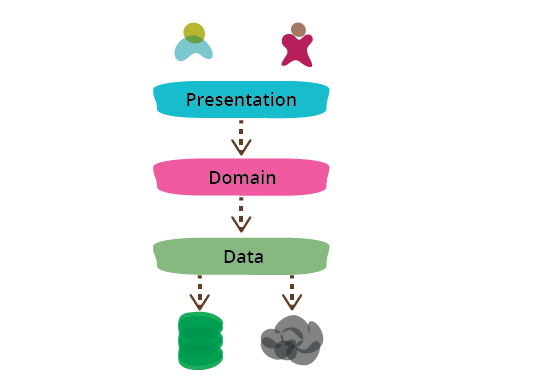
One of the most common ways to modularize an information-rich program is to separate it into three broad layers: presentation (UI), domain logic (aka business logic), and data access. So you often see web applications divided into a web layer that knows about handling HTTP requests and rendering HTML, a business logic layer that contains validations and calculations, and a data access layer that sorts out how to manage persistent data in a database or remote services.
Relational Data Model
The relational data model is best known to most people through relational data bases, and through the SQL language. Colloquially, we think of the database as a set of tables, each row of which contains data. We can manipulate these tables in various ways to do queries, each query results in another table. In contrast to NetworkDataModel, there are no explicit pointers between tables, links are made by join tables on common values (although the use of surrogate keys means you have pointers in practice.)
Reporting Database
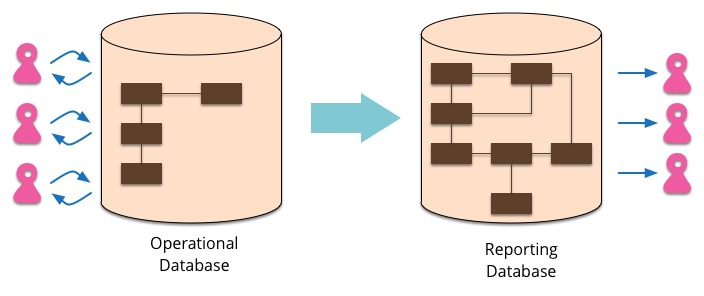
Most EnterpriseApplications store persistent data with a database. This database supports operational updates of the application's state, and also various reports used for decision support and analysis. The operational needs and the reporting needs are, however, often quite different - with different requirements from a schema and different data access patterns. When this happens it's often a wise idea to separate the reporting needs into a reporting database, which takes a copy of the essential operational data but represents it in a different schema.
Resource Pool
Many programs need to make use of resources that are expensive to create and maintain. Examples of these are database connections and threads. A resource pool provides a good way to manage these resources.
Transactionless
A couple of years ago I was talking to a couple of friends of mine who were doing some work at eBay. It's always interesting to hear about the techniques people use on high volume sites, but perhaps one of the most interesting tidbits was that eBay mostly hardly ever uses database transactions.
User Defined Field
A common feature in software systems is to allow users to define their own fields in data structures. Consider an address book - there's a host of things that you might want to add. With new social networks popping up every day, users might want to add a new field for a Bunglr id to their contacts.
goto Aarhus 2011

goto (formerly known as JAOO) has long been a favorite conference of mine. They've done a great job over the years of keeping a high standard of content combined with an efficient and friendly organization. So while my over-consumption of conferences has generally led to conference-phobia, I still feel a sense of pleasant anticipation when heading off for the somewhat complicated trip to Aarhus.