
Data Lake
5 February 2015

Data Lake is a term that's appeared in this decade to describe an important component of the data analytics pipeline in the world of Big Data. The idea is to have a single store for all of the raw data that anyone in an organization might need to analyze. Commonly people use Hadoop to work on the data in the lake, but the concept is broader than just Hadoop.
When I hear about a single point to pull together all the data an organization wants to analyze, I immediately think of the notion of the data warehouse (and data mart 1). But there is a vital distinction between the data lake and the data warehouse. The data lake stores raw data, in whatever form the data source provides. There is no assumptions about the schema of the data, each data source can use whatever schema it likes. It's up to the consumers of that data to make sense of that data for their own purposes.
1: The usual distinction is that a data mart is for a single department in an organization, while a data warehouse integrates across all departments. Opinions differ on whether a data warehouse should be the union of all data marts or whether a data mart is a logical subset (view) of data in the data warehouse.
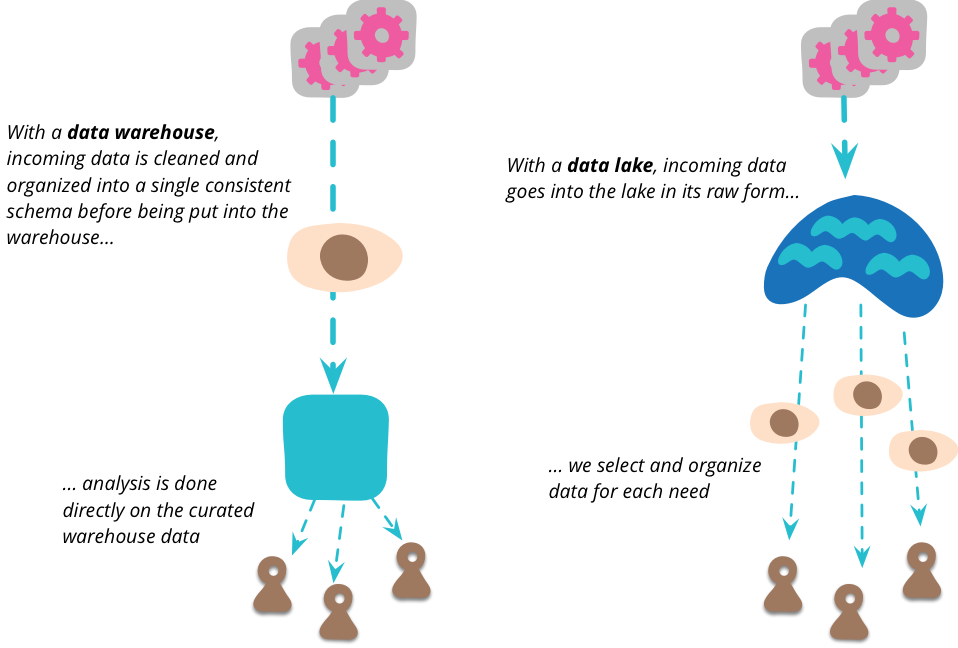
This is an important step, many data warehouse initiatives didn't get very far because of schema problems. Data warehouses tend to go with the notion of a single schema for all analytics needs, but I've taken the view that a single unified data model is impractical for anything but the smallest organizations. To model even a slightly complex domain you need multiple BoundedContexts, each with its own data model. In analytics terms, you need each analytics user to use a model that makes sense for the analysis they are doing. By shifting to storing raw data only, this firmly puts the responsibility on the data analyst.
Another source of problems for data warehouse initiatives is ensuring data quality. Trying to get an authoritative single source for data requires lots of analysis of how the data is acquired and used by different systems. System A may be good for some data, and system B for another. You run into rules where system A is better for more recent orders but system B is better for orders of a month or more ago, unless returns are involved. On top of this, data quality is often a subjective issue, different analysis has different tolerances for data quality issues, or even a different notion of what is good quality.
This leads to a common criticism of the data lake - that it's just a dumping ground for data of widely varying quality, better named a data swamp. The criticism is both valid and irrelevant. The hot title of the New Analytics is “Data Scientist”. Although it's a much-abused title, many of these folks do have a solid background in science. And any serious scientist knows all about data quality problems. Consider what you might think is the simple matter of analyzing temperature readings over time. You have to take into account that some weather stations are relocated in ways that may subtly affect the readings, anomalies due to problems in equipment, missing periods when the sensors aren't working. Many of the sophisticated statistical techniques out there are created to sort out data quality problems. Scientists are always skeptical about data quality and are used to dealing with questionable data. So for them the lake is important because they get to work with raw data and can be deliberate about applying techniques to make sense of it, rather than some opaque data cleansing mechanism that probably does more harm that good.
Data warehouses usually would not just cleanse but also aggregate the data into a form that made it easier to analyze. But scientists tend to object to this too, because aggregation implies throwing away data. The data lake should contain all the data because you don't know what people will find valuable, either today or in a couple of years time.
One of my colleagues illustrated this thinking with a recent example: “We were trying to compare our automated predictive models versus manual forecasts made by the company's contract managers. To do this we decided to train our models on year old data and compare our predictions to the ones made by managers at that time. Since we now know the correct results, this should be a fair test of accuracy. When we started to do this, it appeared that the manager's predictions were horrible and that even our simple models, made in just two weeks, were crushing them. We suspected that this out-performance was too good to be true. After a lot of testing and digging we discovered that the time stamps associated with those manager predictions were incorrect. They were being modified by some end-of-month processing report. So in short, these values in the data warehouse were useless; we feared that we would have no way of performing this comparison. After more digging we found that these reports had been stored and so we could extract the real forecasts made at that time. (We're crushing them again but it's taken many months to get there).”
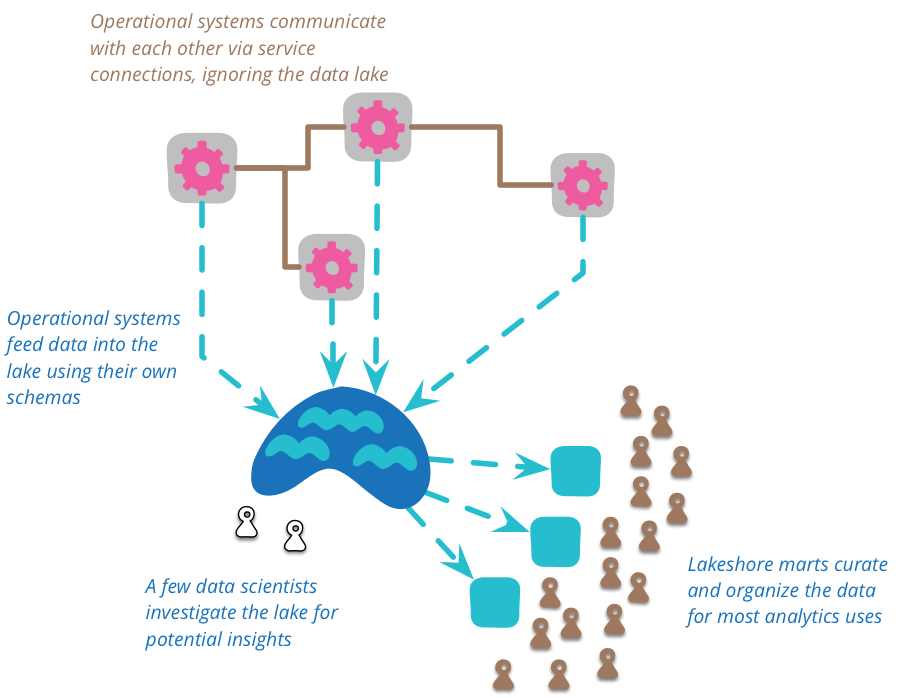
The complexity of this raw data means that there is room for something that curates the data into a more manageable structure (as well as reducing the considerable volume of data.) The data lake shouldn't be accessed directly very much. Because the data is raw, you need a lot of skill to make any sense of it. You have relatively few people who work in the data lake, as they uncover generally useful views of data in the lake, they can create a number of data marts each of which has a specific model for a single bounded context. A larger number of downstream users can then treat these lakeshore marts as an authoritative source for that context.
So far I've described the data lake as singular point for integrating data across an enterprise, but I should mention that isn't how it was originally intended. The term was coined by James Dixon in 2010, when he did that he intended a data lake to be used for a single data source, multiple data sources would instead form a “water garden”. Despite its original formulation the prevalent usage now is to treat a data lake as combining many sources. 2
2: In a later blog post, Dixon emphasizes the lake versus water garden distinction, but (in the comments) says that it is a minor change. For me the key point is that the lake stores a large body of data in its natural state, the number of feeder streams isn't a big deal.
You should use a data lake for analytic purposes, not for collaboration between operational systems. When operational systems collaborate they should do this through services designed for the purpose, such as RESTful HTTP calls, or asynchronous messaging. The lake is too complex to trawl for operational communication. It may be that analysis of the lake can lead to new operational communication routes, but these should be built directly rather than through the lake.
It is important that all data put in the lake should have a clear provenance in place and time. Every data item should have a clear trace to what system it came from and when the data was produced. The data lake thus contains a historical record. This might come from feeding Domain Events into the lake, a natural fit with Event Sourced systems. But it could also come from systems doing a regular dump of current state into the lake - an approach that's valuable when the source system doesn't have any temporal capabilities but you want a temporal analysis of its data. A consequence of this is that data put into the lake is immutable, an observation once stated cannot be removed (although it may be refuted later), you should also expect ContradictoryObservations.
The data lake is schemaless, it's up to the source systems to decide what schema to use and for consumers to work out how to deal with the resulting chaos. Furthermore the source systems are free to change their inflow data schemas at will, and again the consumers have to cope. Obviously we prefer such changes to be as minimally disruptive as possible, but scientists prefer messy data to losing data.
Data lakes are going to be very large, and much of the storage is oriented around the notion of a large schemaless structure - which is why Hadoop and HDFS are usually the technologies people use for data lakes. One of the vital tasks of the lakeshore marts is to reduce the amount of data you need to deal with, so that big data analytics doesn't have to deal with large amounts of data.
The Data Lake's appetite for a deluge of raw data raises awkward questions about privacy and security. The principle of Datensparsamkeit is very much in tension with the data scientists' desire to capture all data now. A data lake makes a tempting target for crackers, who might love to siphon choice bits into the public oceans. Restricting direct lake access to a small data science group may reduce this threat, but doesn't avoid the question of how that group is kept accountable for the privacy of the data they sail on.
Notes
1: The usual distinction is that a data mart is for a single department in an organization, while a data warehouse integrates across all departments. Opinions differ on whether a data warehouse should be the union of all data marts or whether a data mart is a logical subset (view) of data in the data warehouse.
2: In a later blog post, Dixon emphasizes the lake versus water garden distinction, but (in the comments) says that it is a minor change. For me the key point is that the lake stores a large body of data in its natural state, the number of feeder streams isn't a big deal.