
Bitemporal History
It's often necessary to access the historical values of some property. But sometimes this history itself needs to be modified in response to retroactive updates. Bitemporal history treats time as two dimensions: actual history records what history should be given perfect transmission of information, while record history captures how our knowledge of history changes.
07 April 2021

When we think of how some property (e.g. your address or salary) changes over time, we usually think of it as a linear sequence of changes. But surprisingly often, it can get rather more tangled than that, in a way that can often confuse computerized records.
I can illustrate all this with a simple example:
- We are handling payroll for our company. We run the payroll for our company on February 25, and our employee Sally is paid according to her monthly salary of $6000.
- On March 15 we get an apologetic letter from HR telling us that, on February 15th, Sally got a pay raise to $6500.
So what should we answer when we're asked what Sally's salary was on February 25? In one sense we should answer $6500, since we know now that that was the rate. But often we cannot ignore that on Feb 25 we thought the salary was $6000, after all that's when we ran payroll. We printed a check, sent it to her, and she cashed it. These all occurred based on the amount that her salary was. If the tax authorities asked us for her salary on Feb 25, this becomes important.
The Two Dimensions
I find I can make sense of much of this tangle by thinking of time as two dimensions - hence the term “bitemporal”. One dimension is the actual history of Sally's salary, which I'll illustrate by sampling on the 25th of each month, since that's when payroll runs.
| date | salary |
|---|---|
| Jan 25 | 6000 |
| Feb 25 | 6500 |
| Mar 25 | 6500 |
The second dimension comes in as we ask what did we think Sally's salary history was on February 25? On February 25th we hadn't got the letter from HR, so we thought her salary was always $6000. There is a difference between the actual history, and our record of the history. We can show this by adding new dates to our table
| record date | actual date | salary |
|---|---|---|
| Jan 25 | Jan 25 | 6000 |
| Feb 25 | Jan 25 | 6000 |
| Mar 25 | Jan 25 | 6000 |
| Feb 25 | Feb 25 | 6000 |
| Mar 25 | Feb 25 | 6500 |
| Mar 25 | Mar 25 | 6500 |
I'm using the terms actual and record history for the two dimensions. You may also hear people using the terms valid, or effective (for actual) and transaction (for record).1
1:
The terminology of valid time and transaction time comes from Snodgrass, and is also used in the SQL:2011 standard. When I first started giving workshops about temporal modeling, back in the early naughts, I used these terms, but people found them confusing. So instead we started to use actual/record instead. Since valid/transaction hasn't become widespread usage, I'm going to follow that lesson and use actual/record here.
I read the rows of this table by saying something like “on Mar 25th, we thought Sally's salary on Feb 25th was $6500”. Using this way of thinking, I can look at the earlier table of Sally's actual history, and say that more precisely it's Sally's actual history as known (recorded) on March 25.
In programming terms, If I want to know Sally's
salary, and I have no history, then I can get it with something like
sally.salary. To add support for (actual) history I need to use
sally.salaryAt('2021-02-25'). In a bitemporal world I need
another parameter sally.salaryAt('2021-02-25', '2021-03-25')
Another way to visualize this is to make a plot where the x axis is actual time and the y axis is record time. I shade the region according to the salary level. (The shape of the plot is triangular since we're not trying to record future values.2)
2:
With history actual time is always at or before record time. But the notion of bitemporality can apply to the future. If I'm told on May 5 that Sally will get another increase on May 12, then I can record that increase with a record time of May 5 and an actual time of May 12.
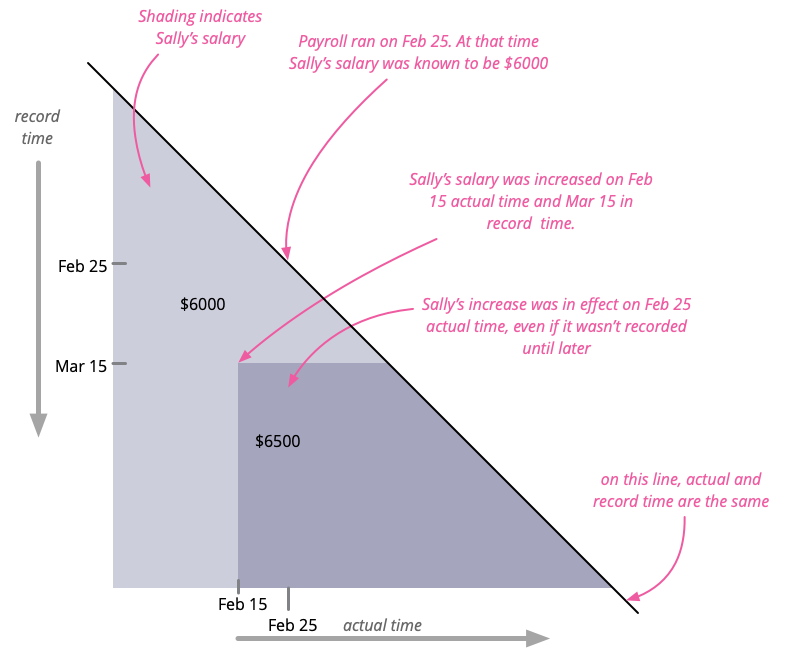
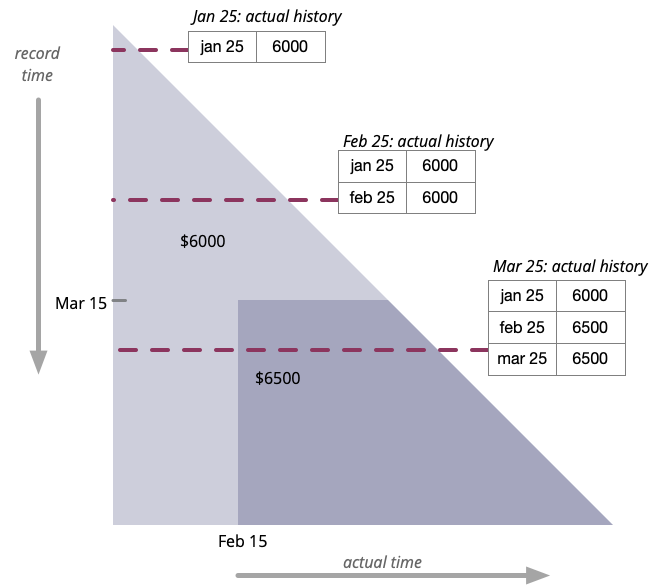
With this plot, I can make a table for how actual history changes with each run of payroll on the 25th. We see that the Feb 25 payroll ran at a time when Sally had no raise, but when the Mar 25 payroll ran, the raise was known.
Changing the Retroactive Change
Now consider another communication from HR
- April 5: Sorry there was an typo in our previous email. Sally's raise on Feb 15 was to $6400. Sorry for the inconvenience.
This is the kind of change that makes angels weep. But when we think of it terms of bitemporal history, it's not that difficult to understand. Here's the plot with this new bit of information.
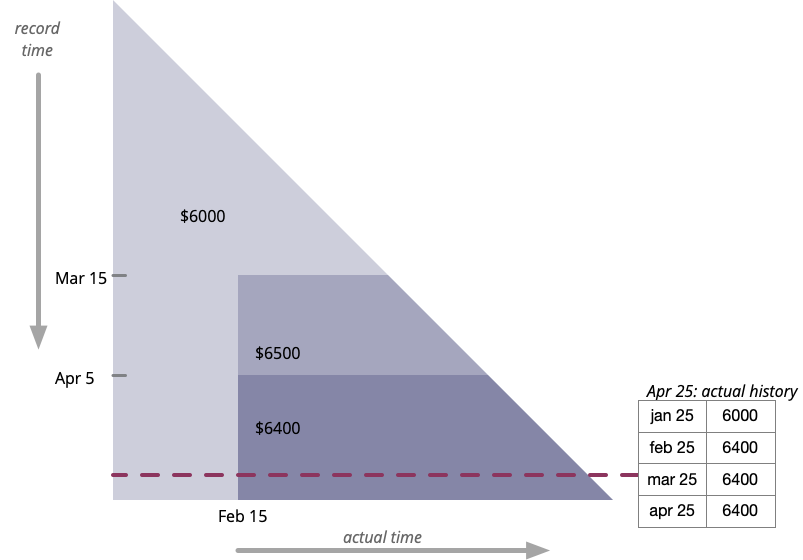
The horizontal lines, used for the payrols, represent the actual history at a certain point in record time. On April 25 we know Sally's salary increased from $6000 to $6400 on February 15. In that perspective, we never see Sally's $6500 salary because it was never true.
Looking at the diagram, what does a vertical line mean?
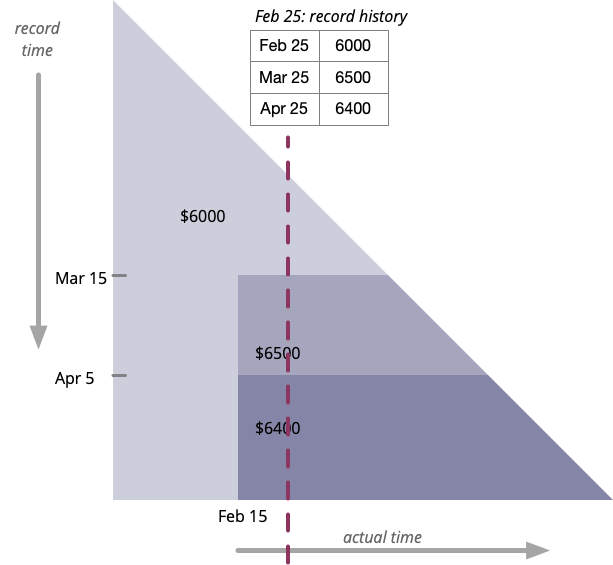
This represents our knowledge of the value at a certain date. The table indicates the recorded salary for February 25th, as our knowledge changed over time.
Using Bitemporality
Bitemporal history is a useful way of framing history when we have to deal with retroactive changes. However we don't see it used that often, partly because many people don't know about the technique, but also because we can often get away without it.
One way to avoid it is to not support retroactive changes. If your insurance company says any changes become in force when they receive your letter - then that's a way of forcing actual time to match record time.
Retroactive changes are a problem when actions are based on a past state that's retroactively changed, such as a salary check being sent out based on a now-updated salary level. If we are merely recording a history, then we don't have to worry about it changing retroactively - we essentially ignore record history and only record actual history. We may do that even when we do have invariant action if the action is recorded in such a way that it records any necessary input data. So the payroll for Sally could record her salary at the time it issues the check, and that's enough for audit purposes. In that situation we can get away with only the actual history of her salary. The record history is then buried inside her payroll statements.
We may also get away with only actual history if any retroactive changes are made before an action occurs. If we had learned of Sally's salary change on February 24th, we could adjust her record without running into before the payroll action relied on the incorrect figure.
If we can avoid using bitemporal history, then that's usually preferable as it does complicate a system quite significantly. However when we have to deal with discrepancies between actual and record history, usually due to retroactive updates, then we need to bite the bullet. One of the hardest parts of this is educating users on how bitemporal history works. Most people don't think of a historical record as something that changes, let alone of the two dimensions of record and actual history.
Append-only History
In a simple world a history is append-only. If communication is perfect and instantaneous then all new information is learned immediately by every interested actor. We can then just treat history as something we add to as new events occur in the world.
Bitemporal history is a way of coming to terms that communication is neither perfect nor instantaneous. Actual history is no longer append-only, we go back and make retroactive changes. However record history itself is append only. We don't change what we thought we knew about Sally's salary on Feb 25. We just append the later knowledge we gained. By layering an append-only record history over the actual history, we allow the actual history to be modified while creating a reliable history of its modifications.
Consequences of Retroactive Changes
Bitemporal history is a mechanism that allows us to track how a value
changes, and it can be extremely helpful to be able ask
sally.salaryAt(actualDate, recordDate). But retroactive
changes do more than just adjust the historical record. As the expert
says: “People assume that time is a strict progression of cause to effect,
but actually from a non-linear, non-subjective viewpoint - it’s
more like a big ball of wibbly wobbly timey wimey stuff.” 3 If we've paid Sally $6000 when we should have paid her
$6400, then we need to make it right. At the very least that means getting
more in a later paycheck, but it may also lead to other consequences.
Maybe the higher payment means she should have crossed some important
threshold a month earlier, maybe there are tax implications.
3: If you don't recognize this quote, you should put Blink on your watchlist. One of the finest time-travel stories ever filmed.
Bitemporal history alone isn't enough to figure out these dependent effects are, that demands a set of additional mechanisms, which are beyond the scope of this pattern. One measure is to create a parallel model, which captures the state of the world as it should have been with the correct salary, and use this to figure out the compensating changes. 4 Bitemporal history can be useful element for these kinds of measures, but only unravels part of that big ball.
4: I started to explore this topic in my earlier writing on parallel models in the mid 2000s. I didn't continue down that path then, and I'm not sure when or if I'll revisit that trail in the future.
Perspectives for Record Time
My example above for record time uses dates to capture our changing understanding of actual history. But the way we capture record history can be more involved than that.
To make everything easier to follow above, I sampled the history on the payroll dates. But a better representation of a history is to use date ranges, Here's a table to cover 2021
| record dates | actual dates | salary |
|---|---|---|
| Jan 1 - Mar 14 | Jan 1 - Dec 31 | 6000 |
| Mar 15 - Apr 4 | Jan 1 - Feb 14 | 6000 |
| Mar 15 - Apr 4 | Feb 15 - Dec 31 | 6500 |
| Apr 5 - Dec 31 | Jan 1 - Feb 14 | 6000 |
| Apr 5 - Dec 31 | Feb 15 - Dec 31 | 6400 |
We can think of Sally's salary being recorded with a combination of two keys, the actual key (a date range) and the record key (also a date range). But our notion of record key can be more complicated than that.
One obvious case is that different agents can have different record histories. This is clearly the case for Sally, it took time to get messages from the HR department to the Payroll department, so the record times for those modifications to actual history will differ between the two.
| department | record dates | actual dates | salary |
|---|---|---|---|
| HR | Jan 1 - Feb 14 | Jan 1 - Dec 31 | 6000 |
| HR | Feb 15 - Dec 31 | Jan 1 - Feb 14 | 6000 |
| HR | Feb 15 - Dec 31 | Feb 15 - Dec 31 | 6400 |
| Payroll | Jan 1 - Mar 14 | Jan 1 - Dec 31 | 6000 |
| Payroll | Mar 15 - Apr 4 | Jan 1 - Feb 14 | 6000 |
| Payroll | Mar 15 - Apr 4 | Feb 15 - Dec 31 | 6500 |
| Payroll | Apr 5 - Dec 31 | Jan 1 - Feb 14 | 6000 |
| Payroll | Apr 5 - Dec 31 | Feb 15 - Dec 31 | 6400 |
Anything that can record a history will have its own record timestamps for when it learns information. Depending on that data we may say that an enterprise will choose a certain agent to be the defining agent for recording certain kinds of data. But agents will cross lines of authority - however big the company, it won't change the recording dates of the tax authorities it deals with. A lot of effort goes into sorting out problems caused by different agents learning the same facts at different times.
We can generalize what's happening here by combining the notion of the department and record date range into a single concept of a perspective. Thus we'd say something like “according to HR's perspective on Feb 25, Sally's salary was $6400”. In a table form, we might visualize it like this.
| perspective | actual dates | salary |
|---|---|---|
| HR, Jan 1 - Feb 14 | Jan 1 - Dec 31 | 6000 |
| HR, Feb 15 - Dec 31 | Jan 1 - Feb 14 | 6000 |
| HR, Feb 15 - Dec 31 | Feb 15 - Dec 31 | 6400 |
| Payroll, Jan 1 - Mar 14 | Jan 1 - Dec 31 | 6000 |
| Payroll, Mar 15 - Apr 4 | Jan 1 - Feb 14 | 6000 |
| Payroll, Mar 15 - Apr 4 | Feb 15 - Dec 31 | 6500 |
| Payroll, Apr 5 - Dec 31 | Jan 1 - Feb 14 | 6000 |
| Payroll, Apr 5 - Dec 31 | Feb 15 - Dec 31 | 6400 |
What does this collapse into a single perspective concept give us? It allows us to think about what other perspectives might be. One example is to consider alternative perspectives. We could create a perspective where we remove individual raises (such as Sally's on Feb 15) and give every employee a salary raise of 10% on March 1st. That would lead to a new record-time dimension for Sally's salary.
| perspective | actual dates | salary |
|---|---|---|
| real world | Jan 1 - Feb 14 | 6000 |
| real world | Feb 15 - Dec 31 | 6400 |
| with global raise | Jan 1 - Feb 28 | 6000 |
| with global-raise | Mar 1 - Dec 31 | 6600 |
This generalization of the notion of record time says that we can layer multiple perspectives over an actual history, using essentially the same mechanism to reason about retroactive changes and alternative histories.
Putting many perspective dimensions over a history isn't something that's widely useful, even compared to bitemporal history. But I find it a helpful way to think about these kinds of situations: reasoning about alternative scenarios, either historically, or in the future. An example of this is budgeting, where different budgets are made in various plans, each with its own forecast, and later compared with actual results.
Storing and Processing Bitemporal Histories
Adding history to data increases complexity. In a bitemporal world I
need two date parameters to access Sally's salary -
sally.salaryAt('2021-02-25', '2021-03-25'). We can simplify
access by defaults, if we treat the default for record time as today, then
processing that only needs current record time can ignore the bitemporal
complications.
Simplifying access, however, doesn't necessarily simplify storage. If any client needs bitemporal data, we have to store it somehow. While there are some databases that have built-in support for for some level of temporality, they are relatively niche. And wisely, folks tend to be extra-wary of niche technologies when it comes to long lived data.
Given that, often the best way is to come up with our own scheme. There are two broad approaches.
The first is to use a bitemporal data structure: encoding the necessary date information into the data structure used to store the data. This could work by using nested date range objects, or a pair of start/end dates in a relational table.
| record start | record end | actual start | actual end | salary |
|---|---|---|---|---|
| Jan 1 | Mar 14 | Jan 1 | Dec 31 | 6000 |
| Mar 15 | Apr 4 | Jan 1 | Feb 14 | 6000 |
| Mar 15 | Apr 4 | Feb 15 | Dec 31 | 6500 |
| Apr 5 | Dec 31 | Jan 1 | Feb 14 | 6000 |
| Apr 5 | Dec 31 | Feb 15 | Dec 31 | 6400 |
This allows access to all the bitemporal history, but is awkward to update and query - although that can be made easier by making a library handle access to bitemporal information.
The alternative is to use event sourcing. Here we don't store the state of Sally's salary as our primary store, instead we store all the changes as events. Such events might look like this
| record date | actual date | action | value |
|---|---|---|---|
| Jan 1 | Jan 1 | sally.salary | 6000 |
| Mar 15 | Feb 15 | sally.salary | 6500 |
| Apr 5 | Feb 15 | sally.salary | 6400 |
Pay attention to the fact that if events need to support bitemporal history, they need to be bitemporal themselves. This means each event needs an actual date (or time) for when the event occurred in the world, and a record date (or time) for when we learned about it.
Storing the events is conceptually more straightforward, but requires more processing to answer a query. However much that processing can cached by building a snapshot of the application's state. So if most users of this data only required current actual history, then we could build a data structure that only supports actual history, populate it from the events, and keep it up to date as new events trickle in. Those users who wanted bitemporal data could create a more complex structure and populate it from the same events, but their complexity wouldn't make things harder for those who wanted the simpler model. (And if some people wanted to look at actual history on a different record date, they could use almost all the same code for working with current actual history.)
Further Reading
I ran into the issues of bitemporal history working with various software systems in the 1980's and 90's. I started to write down the patterns I'd observed, but never got past early drafts before other writing projects took over. There's a discussion of bitemporal history in there, I wrote this article to highlight the concept and hopefully explain it a bit more clearly.
Around that time Richard Snodgrass wrote a book: Developing Time-Oriented Database Applications in SQL. It goes into great detail about how to work with this kind of problem in SQL systems, and its approach influenced the SQL:2011 standard.
I took the notion of perspective from Time Travel: A Pattern Language for Values That Change
Footnotes
1: Actual/record versus valid/transaction
The terminology of valid time and transaction time comes from Snodgrass, and is also used in the SQL:2011 standard. When I first started giving workshops about temporal modeling, back in the early naughts, I used these terms, but people found them confusing. So instead we started to use actual/record instead. Since valid/transaction hasn't become widespread usage, I'm going to follow that lesson and use actual/record here.
2: Bitemporal Future
With history actual time is always at or before record time. But the notion of bitemporality can apply to the future. If I'm told on May 5 that Sally will get another increase on May 12, then I can record that increase with a record time of May 5 and an actual time of May 12.
3: If you don't recognize this quote, you should put Blink on your watchlist. One of the finest time-travel stories ever filmed.
4: I started to explore this topic in my earlier writing on parallel models in the mid 2000s. I didn't continue down that path then, and I'm not sure when or if I'll revisit that trail in the future.
Acknowledgements
Alexandre Klaser, Dave Elliman, Joshua Taylor, Martha Rohte, Mauro Vilasi, Pavlo Kerestey, Pramod Sadalge, Rebecca Parsons, Saager Mhatre, and Wolf Schlegel contributed to a useful discussion of this article on our internal mailing list.
Heikki Heinonen alerted me to some errors in the perspectives tables.
Significant Revisions
07 April 2021: Published
17 March 2021: Sent for internal review
02 March 2021: Started drafting