
Domain Logic and SQL
Over the last couple of decades we've seen a growing gap between database-oriented software developers and in-memory application software developers. This leads to many disputes about how to use database features such as SQL and stored procedures. In this article I look at the question of whether to place business logic in SQL queries or in-memory code, considering primarily performance and maintainability based on an example of a simple, but rich SQL query.
February 2003

Look at any recent book on building enterprise applications (such as my recent P of EAA) and you'll find a breakdown of logic into multiple layers which separate out different parts of an enterprise application. Different authors use different layers, but a common theme is a separation between domain logic (business rules) and data source logic (where data comes from). Since a large part of enterprise application data is stored on relational databases, this layering scheme seeks to separate business logic from the relational database
Many application developers, particularly strong OO developers like myself, tend to treat relational databases as a storage mechanism that is best hidden away. Frameworks exist who tout the advantages of shielding application developers from the complexities of SQL.
Yet SQL is much more than a simple data update and retrieval mechanism. SQL's query processing can perform many tasks. By hiding SQL, application developers are excluding a powerful tool.
In this article I want to explore the pros and cons of using rich SQL queries that may contain domain logic. I have to declare that I bring a OO bias to the discussion, but I've lived on the other side too. (One former client's OO expert group ran me out of the company because I was a “data modeler”.)
Complex Queries
Relational databases all support a standard query language - SQL. Fundamentally I believe that SQL is the primary reason why relational databases have succeeded to the extent they have. A standard way of interacting with databases has provided a strong degree of vendor independence, which both helped the rise of relational databases, and helped see off the OO challenge.
SQL has many strengths, but a particular one is extremely powerful capabilities for querying the database, allowing clients to filter and summarize large amounts of data with very few lines of SQL code. Yet using powerful SQL queries often embed domain logic, which goes against the basic principles of a layered enterprise application architecture.
To explore this topic further, let's play with a simple example. We'll begin with a data model along the lines of Figure 1. Imagine our company has a special discount, which we'll call the Cuillen. Customers qualify for the Cuillen discount if they make at least one order in the month which includes more than $5000 worth of Talisker. Note that two orders in the same month of $3000 each doesn't count, there must be a single order for more than $5000. Let's imagine a you want to look at a particular customer and determine which months in the last year they qualified for a Cuillen discount. I'll ignore the user interface and just assume that what we want is a list of numbers corresponding to their qualifying months.
{kind=link}
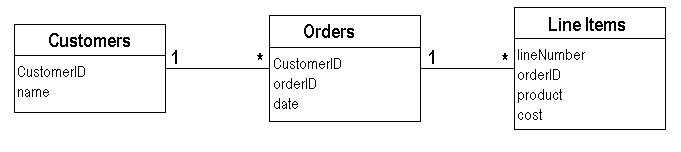
Figure 1: The database schema for the example (UML notation)
There are many ways we can answer this question. I'll begin with three crude alternatives: transaction script, domain model, and complex SQL.
For all these examples, I'm going to illustrate them using the Ruby programming language. I'm going out on a bit of a limb here: usually I use Java and/or C# to illustrate these things as most application developers can read C-based languages. I'm picking Ruby somewhat as an experiment. I like the language because it encourages compact yet well-structured code and makes it easy to write in an OO style. It's my language of choice for scripting. I've added a quick ruby syntax guide based on the ruby I'm using here.
Transaction Script
Transaction script is the pattern name I coined for a procedural style of handling a request in P of EAA. In this case the procedure reads in all the data it might need and then does the selection and manipulation in-memory to figure out which months are needed.
def cuillen_months name
customerID = find_customerID_named(name)
result = []
find_orders(customerID).each do |row|
result << row['date'].month if cuillen?(row['orderID'])
end
return result.uniq
end
def cuillen? orderID
talisker_total = 0.dollars
find_line_items_for_orderID(orderID).each do |row|
talisker_total += row['cost'].dollars if 'Talisker' == row['product']
end
return (talisker_total > 5000.dollars)
end
The two methods, cuillen_months and cuillen?, contain the domain logic. They use a number of “finder” methods that issue queries to the database.
def find_customerID_named name
sql = 'SELECT * from customers where name = ?'
return $dbh.select_one(sql, name)['customerID']
end
def find_orders customerID
result = []
sql = 'SELECT * FROM orders WHERE customerID = ?'
$dbh.execute(sql, customerID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
def find_line_items_for_orderID orderID
result = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh.execute(sql, orderID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
In many ways this is a very simple minded approach, in particular it's very inefficient in its use of SQL - requiring multiple queries to pull back the data (2 + N where N is the number of orders). Don't worry about that too much at the moment, I'll talk about how to improve that later. Concentrate instead on essence of the approach: read in all the data you have to consider, then loop through and select what you need.
(As an aside, the domain logic above is done that way to make it easy to read - but it isn't what I feel is idiomatic Ruby. I'd prefer the method below which makes more use of Ruby's powerful blocks and collection methods. This code will look odd to many people, but Smalltalkers should enjoy it.)
def cuillen_months2 name
customerID = find_customerID_named(name)
qualifying_orders = find_orders(customerID).select {|row| cuillen?(row['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
end
Domain Model
For the second starting point, we'll consider a classical object-oriented domain model. In this case we create in-memory objects, which in this case mirror the database tables (in real systems they usually aren't exact mirrors.) A set of finder objects loads these objects from the database, once we have the objects in memory, we then run the logic on them.
We'll start with the finders. They slam queries against the database and create the objects.
class CustomerMapper
def find name
result = nil
sql = 'SELECT * FROM customers WHERE name = ?'
return load($dbh.select_one(sql, name))
end
def load row
result = Customer.new(row['customerID'], row['NAME'])
result.orders = OrderMapper.new.find_for_customer result
return result
end
end
class OrderMapper
def find_for_customer aCustomer
result = []
sql = "SELECT * FROM orders WHERE customerID = ?"
$dbh.select_all(sql, aCustomer.db_id) {|row| result << load(row)}
load_line_items result
return result
end
def load row
result = Order.new(row['orderID'], row['date'])
return result
end
def load_line_items orders
#Cannot load with load(row) as connection gets busy
orders.each do
|anOrder| anOrder.line_items = LineItemMapper.new.find_for_order anOrder
end
end
end
class LineItemMapper
def find_for_order order
result = []
sql = "select * from lineItems where orderID = ?"
$dbh.select_all(sql, order.db_id) {|row| result << load(row)}
return result
end
def load row
return LineItem.new(row['lineNumber'], row['product'], row['cost'].to_i.dollars)
end
end
These load methods load the following classes
class Customer...
attr_accessor :name, :db_id, :orders
def initialize db_id, name
@db_id, @name = db_id, name
end
class Order...
attr_accessor :date, :db_id, :line_items
def initialize (id, date)
@db_id, @date, @line_items = id, date, []
end
class LineItem...
attr_reader :line_number, :product, :cost
def initialize line_number, product, cost
@line_number, @product, @cost = line_number, product, cost
end
The logic of determining the cuillen months can be described in a couple of methods.
class Customer...
def cuillenMonths
result = []
orders.each do |o|
result << o.date.month if o.cuillen?
end
return result.uniq
end
class Order...
def cuillen?
discountableAmount = 0.dollars
line_items.each do |line|
discountableAmount += line.cost if 'Talisker' == line.product
end
return discountableAmount > 5000.dollars
end
This solution is longer than the transaction script version. However it's worth pointing out that the logic to load the objects and the actual domain logic are more separated. Any other processing on this set of domain objects would use the same load logic. So if we were doing a lot of different bits of domain logic the effort of the load logic would be amortized across all the domain logic, which would make it less of an issue. That cost can be even further reduced by techniques such as Metadata Mapping.
Again there's a lot of SQL queries (2 + number of orders).
Logic in SQL
With both of the first two, the database is used pretty much as a storage mechanism. All we've done is asked for all the records from a particular table with some very simple filtering. SQL is a very powerful query language and can do much more than the simple filtering that these examples use.
Using SQL to its full extent we can do all the work in SQL
def discount_months customerID
sql = <<-END_SQL
SELECT DISTINCT MONTH(o.date) AS month
FROM lineItems l
INNER JOIN orders o ON l.orderID = o.orderID
INNER JOIN customers c ON o.customerID = c.customerID
WHERE (c.name = ?) AND (l.product = 'Talisker')
GROUP BY o.orderID, o.date, c.NAME
HAVING (SUM(l.cost) > 5000)
END_SQL
result = []
$dbh.select_all(sql, customerID) {|row| result << row['month']}
return result
end
Although I've referred to this as a complex query, it's only complex in comparison to the simple select and where clause queries of the earlier examples. SQL queries can get far more complicated than this one, although many application developers would shy away from even a query as minimally complex as this.
Looking at Performance
One of the first questions people consider with this kind of thing is performance. Personally I don't think performance should be the first question. My philosophy is that most of the time you should focus on writing maintainable code. Then use a profiler to identify hot spots and then replace only those hot spots with faster but less clear code. The main reason I do this is because in most systems only a very small proportion of the code is actually performance critical, and it's much easier to improve the performance of well factored maintainable code.
But in any case, let's consider the performance trade-offs first. On my little laptop the complex SQL query performs twenty times faster than the other two approaches. Now you cannot form any conclusions about the the performance of a data center server from an svelte but elderly laptop, but I would be surprised if the complex query would be less than an order of magnitude faster than the in memory approaches.
Part of the reason for this is that the in-memory approaches are written in a way that is very inefficient in terms of SQL queries. As I've pointed out in their descriptions, each one issues a SQL query for every order that a customer has - and my test database has a thousand orders for each customer.
We can reduce this load considerably by rewriting the in-memory programs to use a single SQL query. I'll start with the transaction script.
SQL = <<-END_SQL
SELECT * from orders o
INNER JOIN lineItems li ON li.orderID = o.orderID
INNER JOIN customers c ON c.customerID = o.customerID
WHERE c.name = ?
END_SQL
def cuillen_months customer_name
orders = {}
$dbh.select_all(SQL, customer_name) do |row|
process_row(row, orders)
end
result = []
orders.each_value do |o|
result << o.date.month if o.talisker_cost > 5000.dollars
end
return result.uniq
end
def process_row row, orders
orderID = row['orderID']
orders[orderID] = Order.new(row['date']) unless orders[orderID]
if 'Talisker' == row['product']
orders[orderID].talisker_cost += row['cost'].dollars
end
end
class Order
attr_accessor :date, :talisker_cost
def initialize date
@date, @talisker_cost = date, 0.dollars
end
end
This is a pretty big change to the transaction script, but it speeds things up by a factor of three.
I can do a similar trick with the domain model. Here we see an advantage of the domain model's more complex structure. I only need to modify the loading method, the business logic in the domain objects themselves does not need to change.
class CustomerMapper
SQL = <<-END_SQL
SELECT c.customerID,
c.NAME as NAME,
o.orderID,
o.date as date,
li.lineNumber as lineNumber,
li.product as product,
li.cost as cost
FROM customers c
INNER JOIN orders o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE c.name = ?
END_SQL
def find name
result = nil
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, name) do |sth|
sth.each do |row|
result = load(row) if result == nil
unless result.order(row['orderID'])
result.add_order(om.load(row))
end
result.order(row['orderID']).add_line_item(lm.load(row))
end
end
return result
end
(I'm telling a little lie when I say that I don't need to modify the domain objects. In order to get decent performance I needed to change the data structure of customer so that the orders were held in a hash rather than an array. But again, it was a very self-contained change, and didn't impact the code for determining the discount.)
There's a few points here. Firstly it's worth remembering that in-memory code can often by boosted by more intelligent queries. It's always worth looking to see if you are calling the database multiple times, and if there's a way to do it with a single call instead. This is particularly easy to overlook when you have a domain model because people usually think of class at a time access. (I've even seen cases where people load a single row at a time, but that pathological behavior is relatively rare.)
One of the biggest differences between the transaction script and the domain model is the impact of changing the query structure. For the transaction script, it pretty much means altering the entire script. Furthermore if there were many domain logic scripts using similar data, each one would have to be changed. With the domain model you alter a nicely separated section of the code and the domain logic itself doesn't have to change. This is a big deal if you have a lot of domain logic. This is the general trade off between transaction scripts and domain logic - there's an initial cost in complexity of database access for a domain logic which pays off iff you have a lot of domain logic.
But even with the multi-table query, the in-memory approaches are still not as fast as the complex SQL - by a factor of 6 in my case. This makes sense: the complex SQL does the selection and summing of costs in the database and only has to schlep a handful of values back to the client, while the in-memory approach needs to schlep five thousand rows of data back to the client.
Performance isn't the only factor in deciding what route to go, but it's often a concluding one. If you have a hot spot that you absolutely need to improve, then other factors come second. As a result many fans of domain models follow the system of doing things in-memory as a default, and using things like complex queries for hot spots only when they have to.
It's also worth pointing out that this example is one that plays to a database's strengths. Many queries don't have the strong elements of selection and aggregation that this one does, and won't show such a performance change. In addition multi-user scenarios often cause surprising changes to the way queries behave, so real profiling has to be done under a realistic multi-user load. You may find that locking issues outweigh anything you can get by faster individual queries.
Modifiability
For any long-lived enterprise application, you can be sure of one thing - it's going to change a lot. As a result you have to ensure that the system is organized in such a way that's easy to change. Modifiability is probably the main reason why people put business logic in memory.
SQL can do many things, but there limits to its capabilities. Some things that it can do require quite clever coding, as a browse of algorithms for the median of a dataset displays. Others are impossible to make without resorting to non-standard extensions, which is a problem if you want portability.
Often you want to run business logic before you write data into the database, particularly if you working on some pending information. Loading into a database can be problematic because often you want pending session data to be isolated from fully accepted data. This session data often shouldn't be subject to the same validation rules as fully accepted data.
Understandability
SQL is often seen as a special language, one that's not something that application developers should need to deal with. Indeed many database frameworks like to say how by using them you avoid needing to deal with SQL. I've always found that a somewhat strange argument, since I've always been fairly comfortable with moderately complex SQL. However many developers find SQL harder to deal with than traditional languages, and a number of SQL idioms are hard to fathom to all but SQL experts.
A good test for you is to look at the three solutions, and see which makes the domain logic easiest to follow and thus modify. I find the domain model version, which is just a couple of methods, the easiest to follow; in large part because the data access is separated out. Next I prefer the SQL version over the in-memory transaction script. But I'm sure other readers would have other preferences.
If most of a team is less comfortable with SQL, then that's a reason to keep domain logic away from SQL. (It's also a reason to consider training more people in SQL - at least to an intermediate level.) This is one of those situations where you have to take into account the make up of your team - people do affect architectural decisions.
Avoiding Duplication
One of the simplest, yet most powerful, design principles I've come across is avoiding duplication - formulated by the Pragmatic Programmers as the DRY (Don't Repeat Yourself) principle.
To think about the DRY principle for this case, let's consider another requirement for this application - a list of orders for a customer on a particular month showing the orderID, date, total cost and whether this order is a qualifying order for the Cuillen plan. All of this sorted by the total cost.
Using the domain object approach to handling this query we need to add a method to the order to calculate the total cost.
class Order...
def total_cost
result = 0.dollars
line_items.each {|line| result += line.cost}
return result
end
With that in place then it's easy to print the order list
class Customer
def order_list month
result = ''
selected_orders = orders.select {|o| month == o.date.month}
selected_orders.sort! {|o1, o2| o2.total_cost <=> o1.total_cost}
selected_orders.each do |o|
result << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
end
return result
end
Defining the same query using a single SQL statement requires a correlated sub-query - which some people find daunting.
def order_list customerName, month
sql = <<-END_SQL
SELECT o.orderID, o.date, sum(li.cost) as totalCost,
CASE WHEN
(SELECT SUM(li.cost)
FROM lineitems li
WHERE li.product = 'Talisker'
AND o.orderID = li.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE (c.name = ?)
AND (MONTH(o.date) = ?)
GROUP by o.orderID, o.date
ORDER BY totalCost desc
END_SQL
result = ""
$dbh.select_all(sql, customerName, month) do |row|
result << sprintf("%10d %20s %10s %3s\n",
row['orderID'],
row['date'],
row['totalCost'],
row['isCuillen'])
end
return result
end
Different people will differ about which of these two is the
easiest to understand. But the issue I'm chewing on here is that of
duplication. This query duplicates logic from the original query that
just gives the months. The domain object approach does not have this
duplication - should I wish to change the definition for the cuillen
plan, all I have to do is to alter the definition of
cuillen? and all uses are updated.
Now it isn't fair to trash SQL on the duplication issue - because you can avoid duplication in the rich SQL approach as well. The trick, as database aficionados must be gasping to point out, is to use a view.
I can define a view, for simplicity called Orders2 based on the following query.
SELECT TOP 100 PERCENT
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
CASE WHEN
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker'
AND o.orderID = li2.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.orders o
INNER JOIN dbo.lineItems li ON o.orderID = li.orderID
INNER JOIN dbo.CUSTOMERS c ON o.customerID = c.customerID
GROUP BY o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
I can now use this view for both getting the months and for producing the order list
def cuillen_months_view customerID
sql = "SELECT DISTINCT month(date) FROM orders2 WHERE name = ? AND isCuillen = 'Y'"
result = []
$dbh.select_all(sql, customerID) {|row| result << row[0]}
return result
end
def order_list_from_view customerName, month
result = ''
sql = "SELECT * FROM Orders2 WHERE name = ? AND month(date) = ?"
$dbh.select_all(SQL, customerName, month) do |row|
result << sprintf("%10d %10s %10s\n",
row['orderID'],
row['date'],
row['isCuillen'])
end
return result
end
The view simplifies both the queries and puts the key business logic into a single place.
It seems that people rarely discuss using views like this to avoid duplication. Books I've seen on SQL don't seem to discuss doing this kind of thing. In some environments this is difficult because of the organizational and cultural splits between database and application developers. Often application developers aren't allowed to define views and database developers form a bottleneck that discourages application developers from getting views like this done. DBAs may even refuse to build views that are only needed by a single application. But my opinion is that SQL deserves as much care to design as anything else.
Encapsulation
Encapsulation is a well known principle of object-oriented design, and it's one that I think applies well to general software design. Essentially it says that a program should be divided into modules that hide data structures behind an interface of procedure calls. The purpose of this is to allow you to change the underlying data structure without causing a large ripple effect across the system.
In this case, the question is how can we encapsulate the database? A good encapsulation scheme would allow us to alter the database schema without causing a painful round of editing across an application.
For enterprise applications, a common form of encapsulation is a layering, where we strive to separate domain logic from data source logic. That way the code that works on business logic isn't affected when we alter the database design.
The domain model version is a good example of this kind of encapsulation. The business logic works only on in-memory objects. How the data gets there is completely separated. The transaction script approach has some database encapsulation through the find methods, although the database structure is more revealed through the returning result sets.
In an application world, you achieve encapsulation through an API of procedures and objects. The SQL equivalent is to use views. If you change a table you can create a view which supports the old table. The biggest issue here is with updates, which often can't be done properly with views. This is why many shops wrap all DML with stored procedures.
Encapsulation is about more than just supporting changes to views. It's also about the difference between accessing data and defining business logic. With SQL the two can easily be blurred, yet you can still make some form of separation.
For an example, consider the view I defined above to avoid duplication in queries. That view is a single view which could be split along the lines of a data source and business logic separation. A data source view would look something like this
SELECT o.orderID, o.date, c.customerID, c.name,
SUM(li.cost) AS total_cost,
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker' AND o.orderID =li2.orderID
) AS taliskerCost
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN dbo.lineItems li ON li.orderID = o.orderID
GROUP BY o.orderID, o.date, c.customerID, c.name
We can then use this view in other views that focus more on domain logic. Here's one that indicates the Cuillen eligibility
SELECT orderID, date, customerID, name, total_cost,
CASE WHEN taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
FROM dbo.OrdersTal
This kind of thinking can also be applied to cases where we're loading data into a domain model. Earlier on I talked about how performance issues with a domain model could be dealt with by taking the entire query for cuillen months and substituting it with a single SQL query. Another approach would be to use the above data source view. This would allow us to keep a higher performance while still keeping the domain logic in a domain model. The line items would only be loaded in if necessary using a Lazy Load, but suitable summary information could be brought in via the view.
Using views, or indeed stored procedures, provides encapsulation only up to a point. In many enterprise applications data comes from multiple sources, not just multiple relational databases, but also legacy systems, other applications, and files. Indeed the growth of XML will probably see more data coming from flat files shared via networks. In this case full encapsulation really can only be done by a layer within the application code, which further implies that domain logic should also sit in memory.
Database Portability
One reason why many developers shy away from complex SQL is the issue of database portability. After all the promise of SQL is that it allows you to use the same standard SQL on a bevy of database platforms, allowing to change database vendors easily
In reality that's always been a bit of a fudge. In practice SQL is mostly standard but with all sort of little places to trip you up. With care, however, you can create SQL that isn't too painful to shift between database servers. But to do this you lose a lot of capabilities.
The decision about database portability ends up being particular to your project. These days it's much less of an issue than it used to be. The database market has shaken out so most places fall into one of the three major camps. Corporations often have strong commitments to whichever camp they are in. If you consider that changing databases is very unlikely due to this kind of investment, you might as well start taking advantage of the special features your database provides.
Some people still need portability, such as people who provide products that can be installed and interfaced with multiple databases. In this case there is a stronger argument against putting logic into SQL since you have to be so careful about which parts of SQL you can safely use.
Testability
Testability isn't a topic that's tended to come up enough in discussions about design. One of the benefits of Test Driven Development (TDD) is that it's rekindled the notion that testability is a vital part of design.
Common practice in SQL seems to not test. Indeed it's not uncommon to find essential views and stored procedures not even held in configuration management tools. Yet it's certainly possible to have testable SQL. The popular xunit family has a number of tools that can be used for testing within a database environment. Evolutionary database techniques such as test databases can be used to provide a testable environment very similar to what TDD programmers enjoy.
The main area that can make a difference is performance. While direct SQL is often faster in production, it can be much faster to run tests on business logic in memory if the database interface is designed in such a way that you can replace the actual database connection with a Service Stub.
Summing Up
So far I've talked about the issues. Now it's time to draw conclusions. Fundamentally what you have to do is to consider the various issues I've talked about here, judge them by your biases, and decide which policy to take to using rich queries and putting domain logic in there.
The way I look at the picture, one of the most critical elements is whether your data comes from a single logical relational database, or is scattered across a mass of different, often non-SQL, sources. If it's scattered then you should build a data source layer in memory to encapsulate your data sources and keep your domain logic in memory. In this case the strengths of SQL as a language isn't an issue, because not all of your data is in SQL.
The situation becomes interesting when the vast majority of your data sits in a single logical database. In this case you have two primary issues to consider. One is the choice of programming language: SQL versus your application language. The other is where the code runs, SQL at the database, or in memory.
SQL makes some things easy, but other things more difficult. Some people find SQL easy to work with, others find it horribly cryptic. The teams personal comfort is a big issue here. I would suggest that if you go the route of putting a lot of logic in SQL, don't expect to be portable - use all of your vendors extensions and cheerfully bind yourself to their technology. If you want portability keep logic out of SQL.
So far I've talked about modifiability issues. I think these concerns should come first, but be trumped by any critical performance issues. If you use an in-memory approach and have hot-spots that can be solved by more powerful queries, then do that. I would suggest looking to see how much you can organize performance enhancing queries as data source queries, as I outlined above. That way you can minimize putting domain logic into the SQL.
Significant Revisions
February 2003: