
tagged by: API design
Public versus Published Interfaces
Many modern languages make a distinction between public and private features in a module. A distinction that doesn't get made so often is between public and published features: and that may be a more important distinction.
Refactoring Module Dependencies
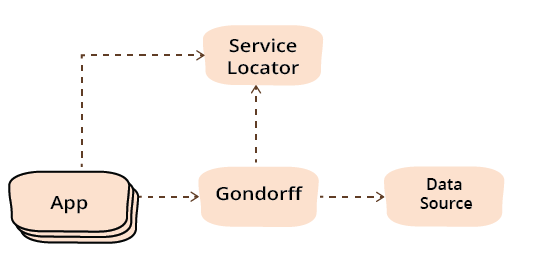
As a program grows in size it's important to split it into modules, so that you don't need to understand all of it to make a small modification. Often these modules can be supplied by different teams and combined dynamically. In this refactoring essay I split a small program using Presentation-Domain-Data layering. I then refactor the dependencies between these modules to introduce the Service Locator and Dependency Injection patterns. These apply in different languages, yet look different, so I show these refactorings in both Java and a classless JavaScript style.
Collection Pipeline
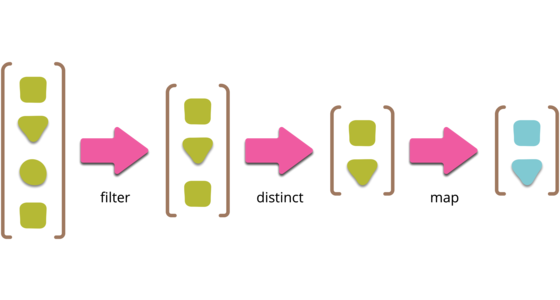
Collection pipelines are a programming pattern where you organize some computation as a sequence of operations which compose by taking a collection as output of one operation and feeding it into the next. (Common operations are filter, map, and reduce.) This pattern is common in functional programming, and also in object-oriented languages which have lambdas. This article describes the pattern with several examples of how to form pipelines, both to introduce the pattern to those unfamiliar with it, and to help people understand the core concepts so they can more easily take ideas from one language to another.
Refactoring with Codemods to Automate API Changes
Refactoring is something developers do all the time—making code easier to understand, maintain, and extend. While IDEs can handle simple refactorings with just a few keystrokes, things get tricky when you need to apply changes across large or distributed codebases, especially those you don’t fully control. That’s where codemods come in. By using Abstract Syntax Trees (AST), codemods allow you to automate large-scale code changes with precision and minimal effort, making them especially useful when dealing with breaking API changes. This article looks at how codemods can help manage these challenges, with practical examples like removing feature toggles or refactoring complex React components. We’ll also discuss potential pitfalls and how to avoid them when using codemods at scale.
Microservices and the First Law of Distributed Objects
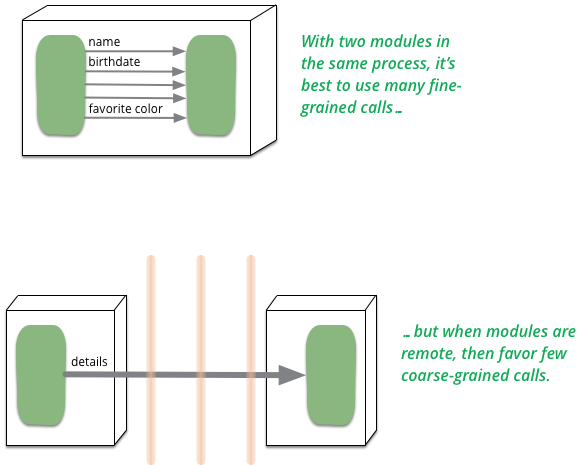
In P of EAA I said "don't distribute your objects". Does this advice contradict my interest in Microservices?
APIs should not be copyrightable
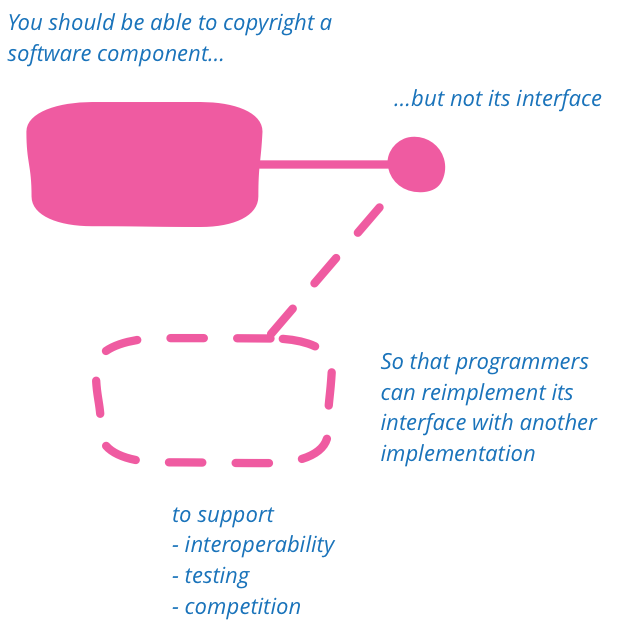
APIs should not be copyrightable so that programmers can reimplement interfaces to support testing, interoperability, and to encourage competition.
Bitemporal History
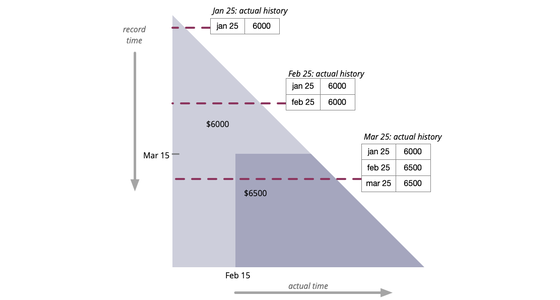
It's often necessary to access the historical values of some property. But sometimes this history itself needs to be modified in response to retroactive updates. Bitemporal history treats time as two dimensions: actual history records what history should be given perfect transmission of information, while record history captures how our knowledge of history changes.
CQRS
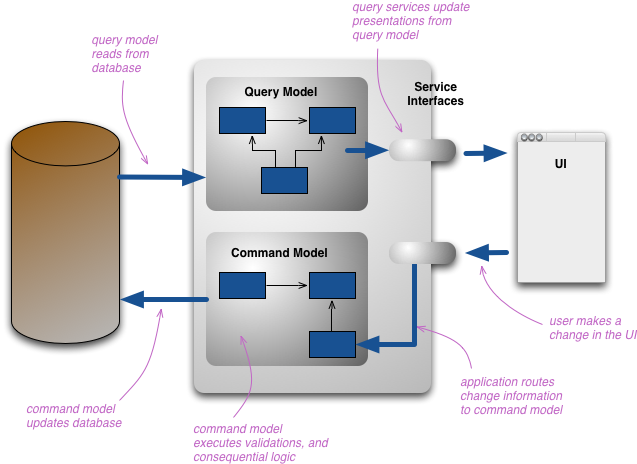
CQRS stands for Command Query Responsibility Segregation. It's a pattern that I first heard described by Greg Young. At its heart is the notion that you can use a different model to update information than the model you use to read information. For some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity.
Command Oriented Interface
The most common style of interface to a module is to use procedures, or object methods. So if you want a module to calculate a bunch of charges for a contract, you might have a BillingService class with a method for doing the calculation, calling it like this
aBillingService.calculateCharges(aContract)
A command oriented interface would have a command class for each operation, and be called with something like this
CalculateChargeCommand.new(aContract).run()
Command Query Separation
The term 'command query separation' was coined by Bertrand Meyer in his book “Object Oriented Software Construction“ - a book that is one of the most influential OO books during the early days of OO. (The first edition is the one that had the influence, the second edition is good but you'll need several months in a gym before you can lift it.)
Constructor Initialization
Constructor initialization is an approach where you pass in all the collaborators that the object needs in the creation method of the object. It is an alternative to SetterInitialization.
Courtesy Implementation
When you a write a class, you mostly strive to ensure that the features of that class make sense for that class. But there are occasions when it makes sense to add a feature to allow a class to conform to a richer interface that it naturally should.
Decorated Command
This is a very common pattern and also very simple, it's really just the decorator pattern applied to commands. I've seen it used a lot with CommandOrientedInterfaces. You also hear this referred to as interceptors and as a form of Aspect Oriented Programming.
Designed Inheritance
One of the longest running arguments on object-oriented circles is the debate between OpenInheritance and Designed Inheritance. The principle of Designed Inheritance is probably best summed up by Josh Bloch: “Design and document for inheritance or else prohibit it”. With this approach you take care to decide which methods can be inherited and Seal the others to stop them being overridden.
Duck Interface
Perhaps I was being naive but I never expected quite the chatter that my post on HumaneInterface opened up. Sadly most of it ended up being arguments about the relative merits of Ruby's Array and Java's List rather than the underlying points I was trying to make, but despite that I think some nice conversational tributaries appeared.
One of these conversational threads brought out that there are other reasons for the differences between Array and List than the humane/minimal philosophies. One of these reasons has to do with the way similar functionality plays different roles in the two languages.
Flag Argument
A flag argument is a kind of function argument that tells the function to carry out a different operation depending on its value. Let's imagine we want to make booking for a concert. There are two ways to do this: regular and premium . To use a flag argument here we'd end up with a method declaration along these lines:
Fluent Interface
A few months ago I attended a workshop with Eric Evans, and he talked about a certain style of interface which we decided to name a fluent interface. It's not a common style, but one we think should be better known. Probably the best way to describe it is by example.
Foundation Platform
A Foundation Platform is a that is built prior to any application that are built on top of it. The idea is that you analyze the needs of the various applications that need the platform, then you build the platform. Once the platform is complete you then build applications on top of it. The point is that the platform really needs to have a stable API before you start work on the applications, otherwise changes to the platform will be hard to manage due to their knock-on effects with the applications.
Getter Eradicator
You can tell them by the twitch in the left hand side of the mouth when they see a getter method, there's swift pull on their battleaxe and a satisfied cry as another getter is hewn unmercifully from a class which immediately swoons in an ecstasy of gratefulness at the manly Getter Eradicator's feet.
Harvested Platform
To build a platform by harvesting, you start by not trying to build a platform, but by building an application. While you build the application you don't try to develop generic code, but you do work hard to build a well-factored and well designed application.
Header Interface
A header interface is an explicit interface that mimics the implicit public interface of a class. Essentially you take all the public methods of a class and declare them in an interface. You can then supply an alternative implementation for the class. This is the opposite of a RoleInterface - I discuss more details and the pros and cons there.
Hollywood Principle
A synonym for InversionOfControl.
Humane Interface
Hanging around the ruby crowd for a while, I've come across the term 'Humane Interface' quite a bit. It describes part of the rubyist attitude to writing class interfaces, I think it also sets up an interesting contrast between two schools of thought in designing APIs (the other is the MinimalInterface).
Implicit Interface Implementation
Both Java and C# share the same model of pure interface
types. You declare a pure interface by going interface
Mailable, then you can declare you implement it with
class Customer implements Mailable (in Java). A class
may implement any number of pure interfaces. One of the things this
model ignores is that you have implicit interfaces whenever
you have a class.
Interface Implementation Pair
The practice of taking every class and pairing it with an interface. So as a result you see pairs of things - maybe ICustomer and Customer or Customer and CustomerImpl. In many ways it echoes the C/C++ habit of header files for each class, although in this case the interfaces and implementations are actually separate types.
Inversion Of Control
Inversion of Control is a common phenomenon that you come across when extending frameworks. Indeed it's often seen as a defining characteristic of a framework.
Minimal Interface
A minimal interface is a style of API design which I contrast here to a HumaneInterface. The idea behind the minimal interface is to design an API that allows the client to do everything they need to do, but boils down the capabilities to the smallest reasonable set of methods that will do the job. (See HumaneInterface for a good example of the difference.)
Open Inheritance
This is the opposite attitude to DesignedInheritance. Advocates of open inheritance do not look to disallow inheritance by Sealing their classes or doing anything else to stop people inheriting classes.
Overloaded Getter Setter
I've been poking around in JavaScript recently and one thing
that's struck me is the habit of using the same function name for a
getter and a setter. So if you want to find out the height of your
banner in jQuery you would use $(“#banner”).height()
and if you want to change the height you would use
$(“#banner”).height(100).
This convention is familiar to me, as it was used by
Smalltalk. You might get a value with banner height
and change it with banner height: 100. Knowing it was
a smalltalk convention is enough to expect me to like it, since I
have an distant but abiding love for that language. But even the
best things have flaws, and I can't hide my dislike for this coding
style.
Parallel Change
Making a change to an interface that impacts all its consumers requires two thinking modes: implementing the change itself, and then updating all its usages. This can be hard when you try to do both at the same time, especially if the change is on a PublishedInterface with multiple or external clients.
Parallel change, also known as expand and contract, is a pattern to implement backward-incompatible changes to an interface in a safe manner, by breaking the change into three distinct phases: expand, migrate, and contract.
Published Interface
Published Interface is a term I used (first in Refactoring) to refer to a class interface that's used outside the code base that it's defined in. As such it means more than public in Java and indeed even more than a non-internal public in C#. In my column for IEEE Software I argued that the distinction between published and public is actually more important than that between public and private.
Required Interface
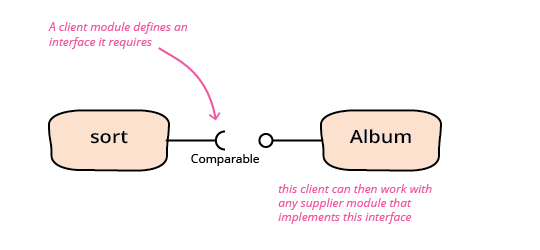
A required interface is an interface that is defined by the client of an interaction that specifies what a supplier component needs to do so that it can be used in that interaction.
Role Interface
A role interface is defined by looking at a specific interaction between suppliers and consumers. A supplier component will usually implement several role interfaces, one for each of these patterns of interaction. This contrasts to a HeaderInterface, where the supplier will only have a single interface.
Rules Engine
Should I use a Rules Engine?
Seal
Sealing a method or a class prevents subclasses from overriding it.
Setter Initialization
With setter initialization you construct an empty object and then use setter methods to setup various properties as you go. (An alterative to ConstructorInitialization.)
Software Development Attitude
Many debates in software development are underpinned by whether the speaker has a DirectingAttitude or an EnablingAttitude. These different attitudes affect choices over languages, designs, tools, processes, and lots more.
Tell Dont Ask
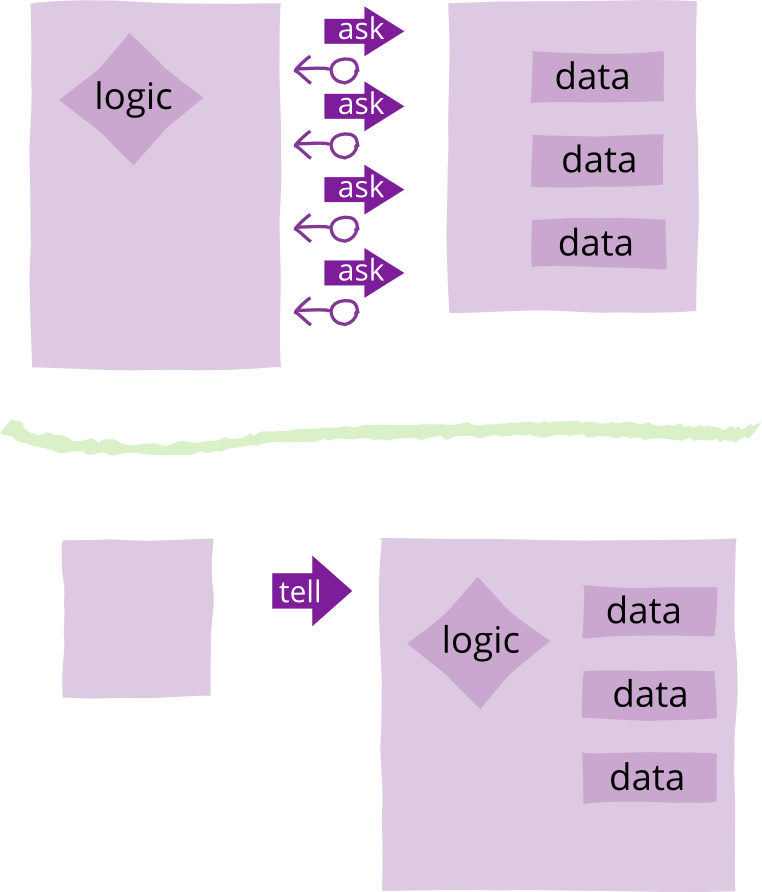
Tell-Don't-Ask is a principle that helps people remember that object-orientation is about bundling data with the functions that operate on that data. It reminds us that rather than asking an object for data and acting on that data, we should instead tell an object what to do. This encourages to move behavior into an object to go with the data.
Two Hard Things
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Typed Collection
When people are starting to work with objects, particularly in a
strongly typed language, a common question is whether they should
have specific collection classes for different domain types. So if
you have a company class which stores a collection of employees,
should you use a regular collection class from your libraries, or
should you create a specific EmployeeList class - a
typed collection.
Uniform Access Principle
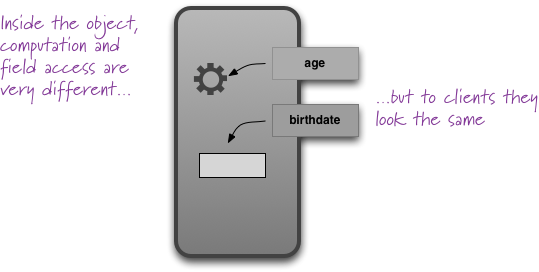
All services offered by a module should be available through a uniform notation, which does not betray whether they are implemented through storage or through computation.
-- Bertrand Meyer
Bertrand Meyer coined this principle in his highly-influential book Object-Oriented Software Construction.
The essential point of the principle is that if you have a person object and you ask it for its age, you should use the same notation whether the age is a stored field of the object or a computed value. It effectively means that a client of the person should neither know nor care whether the age is stored or computed.
User Defined Field
A common feature in software systems is to allow users to define their own fields in data structures. Consider an address book - there's a host of things that you might want to add. With new social networks popping up every day, users might want to add a new field for a Bunglr id to their contacts.
Value Object
When programming, I often find it's useful to represent things as a compound. A 2D coordinate consists of an x value and y value. An amount of money consists of a number and a currency. A date range consists of start and end dates, which themselves can be compounds of year, month, and day.
As I do this, I run into the question of whether two compound objects are the same. If I have two point objects that both represent the Cartesian coordinates of (2,3), it makes sense to treat them as equal. Objects that are equal due to the value of their properties, in this case their x and y coordinates, are called value objects.