
Expanding the solution size with multi-file editing

Birgitta is a Distinguished Engineer and AI-assisted delivery expert at Thoughtworks. She has over 20 years of experience as a software developer, architect and technical leader.

This article is part of “Exploring Gen AI”. A series capturing Thoughtworks technologists' explorations of using gen ai technology for software development.
19 November 2024
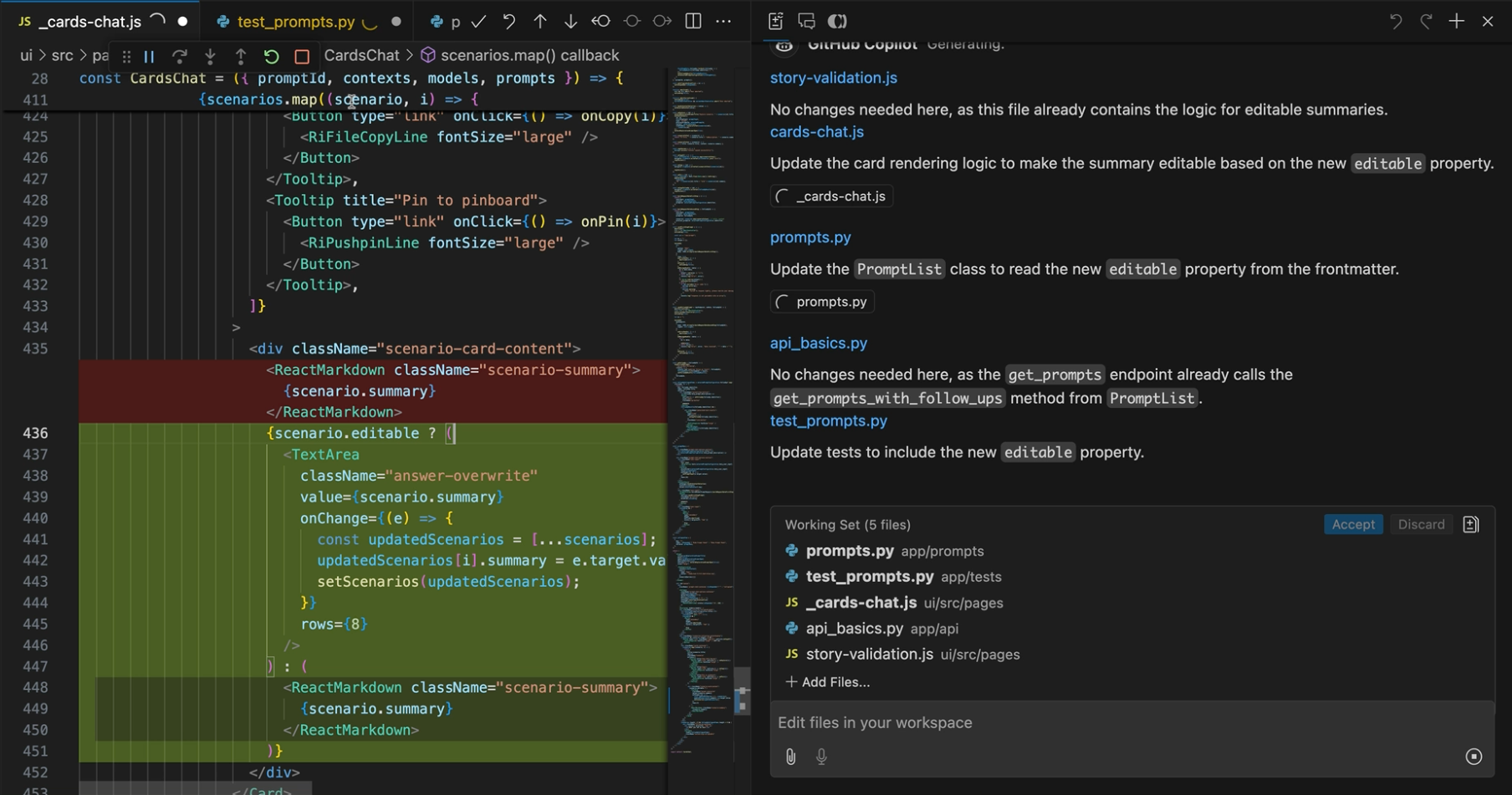
A very powerful new coding assistance feature made its way into GitHub Copilot at the end of October. This new “multi-file editing” capability expands the scope of AI assistance from small, localized suggestions to larger implementations across multiple files. Previously, developers could rely on Copilot for minor assistance, such as generating a few lines of code within a single method. Now, the tool can tackle larger tasks, simultaneously editing multiple files and implementing several steps of a larger plan. This represents a step change for coding assistance workflows.
Multi-file editing capabilities have been available in open-source tools like Cline and Aider for some time, and Copilot competitor Cursor has a feature called “Composer” (though also very new and still undocumented) that bears a striking resemblance to the Copilot multi-editing experience. Codeium have also just released a new editor called Windsurf that advertises these capabilities. The arrival of this feature in GitHub Copilot however makes it available to the userbase of the currently most adopted coding assistant at enterprises.
What is multi-file editing?
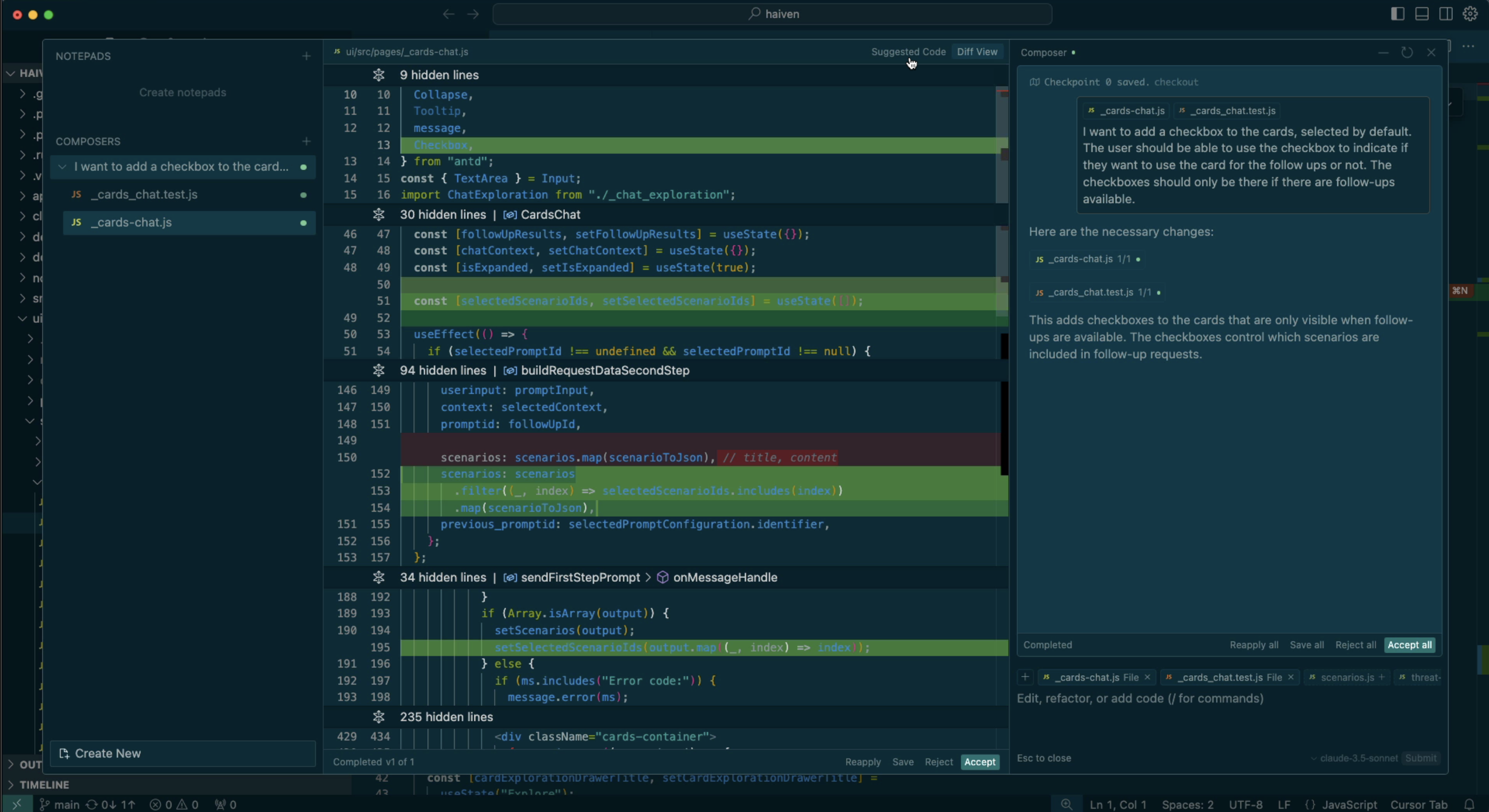
Here is how it works in Copilot and Cursor:
- Provide textual instructions of what you want to do
- Select a set of files that you want the tool to read and change. This step varies across tools, Cline and Windsurf try to determine the files that need to be changed automatically.
- Wait! I’d estimate it took 30-60 seconds, for the tasks I tried it with.
- Go through the diffs that were created and review them
- Adapt the changes yourself, or give the tool further corrective instructions if necessary.
- Once you’re happy with the changes, you can “Accept” them.
- You can continue the session with further instructions that will create new change sets on top of your already accepted changes.
Example from GitHub Copilot:
Example from Cursor’s Composer:
What to consider when using multi-file editing
Problem size
A key for effective usage of this will be how we describe what we want AI to do, and which size of problem we use it for.
The larger the problem, …
- …the more code context needed for AI
- …the higher the probability to run into token limits
- …the higher the probability of AI getting things wrong
- …the higher the risk of the human missing problematic changes
- …the larger the commit size, keeping in mind that large change set sizes increase deployment risk and make rollbacks and incident debugging harder
I used Copilot to add a new feature that
- Loads a new boolean property from my data source
- Forwards that new property as part of my API endpoint to the frontend
- The frontend uses it to determine editability of an element on the page
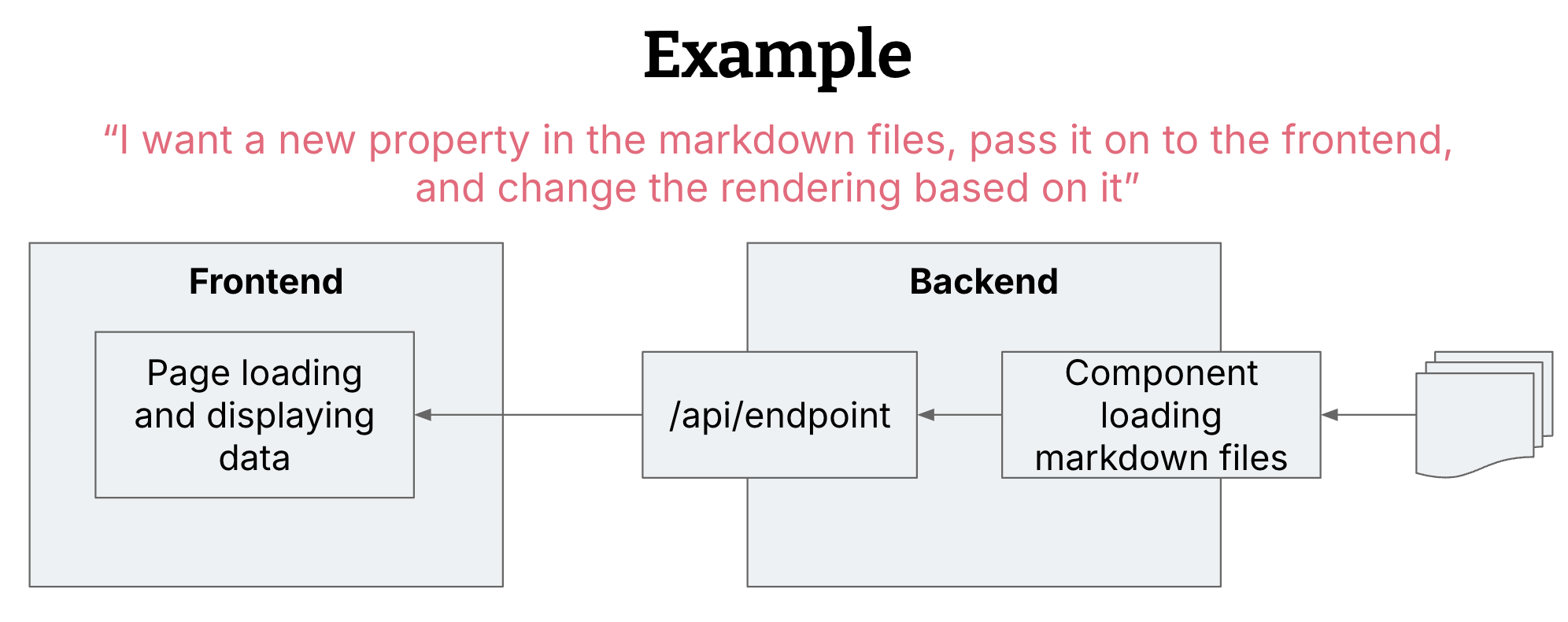
This seems like a nice change and commit size to me, and one that is not too big for AI to work on reliably. Other people might argue though that they would usually break this up into three commits. As soon as you break this down into three separate changes though, it doesn’t make sense anymore to use multi-file edits, as it’s small enough to use the more conventional AI features like inline completions. So this feature definitely influences us to do larger commits rather than very small ones.
I would expect these tools to soon automatically determine for me what files need to change (which is by the way what Cline already does). However, having to manually choose a limited set of files to expose to the editing session could also be a good feature, because it forces us into smaller and therefore less risky change sets. Interestingly, this is yet another case of “AI works better with well-factored code” - the more modularised your codebase, and the better your separation of concerns, the easier it is to give AI a nice separated section of code to work on. If you keep finding yourself annoyed by the constraint that you can only provide AI with a few files, and not throw the whole codebase at it, that could be a smell of your codebase design.
Problem description - or implementation plan?
Note how in the example above, I’m actually describing an implementation plan to the tool, not really a problem to be solved. As I also have to predetermine which files need to be changed, I have to have a rough idea of the implementation already anyway, so the tool has forced me a bit into this low abstraction level.
One might argue that if I have to come with an implementation plan already, then is it even worth using the feature? Isn’t AI meant to help us solve problems in this next step, not just follow implementation plans? I personally still really liked using this, and found it valuable, because it reduced my cognitive load for making some relatively straightforward changes. I didn’t have to think about which methods exactly I had to change, find the right integration points, etc.
It would be interesting to try a workflow where I come up with an implementation plan in the regular coding assistant chat first, resulting in a plan and a list of files to feed into the multi-file edit mode.
Review experience
Another crucial factor for the effectiveness of multi-file editing is the review experience for the developer. How easy or hard does the tool make it for me to understand what was changed, and reason about if they are good changes? In all of these tools the review experience is basically the same as going through your own changes and doing a final check before you commit: Walking through each changed file and looking at every single diff in that file. So it feels familiar.
Some first observations I have from reviewing multi-file changes:
- It’s not uncommon at all to find a few unnecessary changes. Either a slight refactoring of a function that wasn’t even relevant, or in one case some additional test assertions in existing tests that were unnecessary and would have made my tests more brittle. So it’s important to have a close look.
- I had some instances of AI reformatting existing code without any substantial change. This extended my review time, and again, I had to be extra careful to not accept a change that was irrelevant or unintentionally changing behaviour. Different code formatting styles and settings are of course a common problem among human developers as well, but we have deterministic tools for that, like running linters in pre-commit hooks.
- I needed some time to figure out the multi-step changes: Ask for a change, review, accept. Ask for another change, and I get a change set on top of my last change, not all changes done so far in the session. It takes some getting used to what diffs I’m seeing where.
A last note on code review: As it becomes even easier to do larger functional changes with AI, hopefully this doesn’t lead to developers accepting AI changes with only a cursory look and test, and “delegating” the actual review to the colleague who will look at the pull request…
Feedback loop
As the problems that can be tackled by coding assistants get bigger, I’m wondering about the feedback loops we should use to help us safeguard AI changes. My change example from above cannot be tested with one or two unit tests, it needed updates to a backend unit test, an API integration test, and a frontend component test. There were no functional E2E tests in this codebase, but in some codebases that would be yet another test to consider. At this stage, I wouldn’t trust a coding assistant to make decisions about my testing pyramid for me.
In any case, I found it helpful to start my code review with the tests that were changed, giving me an entry point into the AI’s understanding of the task.
Conclusions
Multi-file editing is a very powerful feature that comes with a new set of possibilities, but also increases the AI blast radius. While I think it is relatively easy to start using the simpler coding assistance features we had so far (inline assistance and chat), this one will take more time to figure out and use responsibly.
latest article (Jul 08):
previous article:
next article: