
Using the cloud to scale Etsy
29 November 2022

Tim Cochran is a Technical Director for the US East Market at Thoughtworks. Tim has over 19 years of experience leading work across startups and large enterprises in various domains such as retail, financial services, and government. He advises organizations on technology strategy and making the right technology investments to enable digital transformation goals. He is a vocal advocate for the developer experience and passionate about using data-driven approaches to improve it.

Keyur is the Chief Architect and VP of Infrastructure Engineering at Etsy. He has led multiple large architectural changes during his tenure, most recently the move to Google Cloud. Prior to this role, he was a key member of the Systems Engineering team helping scale the site and keeping PHP, MySQL, Memcached, Redis, and the Linux kernel running smoothly.

This article is part of the series: Bottlenecks of Scaleups
Contents
- Strategic Principles
- Using a partner
- An incremental federated approach
- The challenges of observing everything
- Migration to the cloud-enabled a better ML platform
- What were the challenges of the cloud?
- The stress test of the pandemic
- Continually Improving the platform
- Measuring Cost and Carbon Consumption
Etsy, an online marketplace for unique, handmade, and vintage items, has seen high growth over the last five years. Then the pandemic dramatically changed shoppers’ habits, leading to more consumers shopping online. As a result, the Etsy marketplace grew from 45.7 million buyers at the end of 2019 to 90.1 million buyers (97%) at the end of 2021 and from 2.5 to 5.3 million (112%) sellers in the same period.
The growth massively increased demand on the technical platform, scaling traffic almost 3X overnight. And Etsy had signifcantly more customers for whom it needed to continue delivering great experiences. To keep up with that demand, they had to scale up infrastructure, product delivery, and talent drastically. While the growth challenged teams, the business was never bottlenecked. Etsy’s teams were able to deliver new and improved functionality, and the marketplace continued to provide a excellent customer experience. This article and the next form the story of Etsy’s scaling strategy.
Etsy's foundational scaling work had started long before the pandemic. In 2017, Mike Fisher joined as CTO. Josh Silverman had recently joined as Etsy’s CEO, and was establishing institutional discipline to usher in a period of growth. Mike has a background in scaling high-growth companies, and along with Martin Abbott wrote several books on the topic, including The Art of Scalability and Scalability Rules.
Etsy relied on physical hardware in two data centers, presenting several scaling challenges. With their expected growth, it was apparent that the costs would ramp up quickly. It affected product teams’ agility as they had to plan far in advance for capacity. In addition, the data centers were based in one state, which represented an availability risk. It was clear they needed to move onto the cloud quickly. After an assessment, Mike and his team chose the Google Cloud Platform (GCP) as the cloud partner and started to plan a program to move their many systems onto the cloud.
While the cloud migration was happening, Etsy was growing its business and its team. Mike identified the product delivery process as being another potential scaling bottleneck. The autonomy afforded to product teams had caused an issue: each team was delivering in different ways. Joining a team meant learning a new set of practices, which was problematic as Etsy was hiring many new people. In addition, they had noticed several product initiatives that did not pay off as expected. These indicators led leadership to re-evaluate the effectiveness of their product planning and delivery processes.
Strategic Principles
Mike Fisher (CTO) and Keyur Govande (Chief Architect) created the initial cloud migration strategy with these principles:
Minimum viable product - A typical anti-pattern Etsy wanted to avoid was rebuilding too much and prolonging the migration. Instead, they used the lean concept of an MVP to validate as quickly and cheaply as possible that Etsy’s systems would work in the cloud, and removed the dependency on the data center.
Local decision making - Each team can make its own decisions for what it owns, with oversight from a program team. Etsy’s platform was split into a number of capabilities, such as compute, observability and ML infra, along with domain-oriented application stacks such as search, bid engine, and notifications. Each team did proof of concepts to develop a migration plan. The main marketplace application is a famously large monolith, so it required creating a cross-team initiative to focus on it.
No changes to the developer experience - Etsy views a high-quality developer experience as core to productivity and employee happiness. It was important that the cloud-based systems continued to provide capabilities that developers relied upon, such as fast feedback and sophisticated observability.
There also was a deadline associated with existing contracts for the data center that they were very keen to hit.
Using a partner
To accelerate their cloud migration, Etsy wanted to bring on outside expertise to help in the adoption of new tooling and technology, such as Terraform, Kubernetes, and Prometheus. Unlike a lot of Thoughtworks’ typical clients, Etsy didn’t have a burning platform driving their fundamental need for the engagement. They are a digital native company and had been using a thoroughly modern approach to software development. Even without a single problem to focus on though, Etsy knew there was room for improvement. So the engagement approach was to embed across the platform organization. Thoughtworks infrastructure engineers and technical product managers joined search infrastructure, continuous deployment services, compute, observability and machine learning infrastructure teams.
An incremental federated approach
The initial “lift & shift” to the cloud for the marketplace monolith was the most difficult. The team wanted to keep the monolith intact with minimal changes. However, it used a LAMP stack and so would be difficult to re-platform. They did a number of dry runs testing performance and capacity. Though the first cut-over was unsuccessful, they were able to quickly roll back. In typical Etsy style, the failure was celebrated and used as a learning opportunity. It was eventually completed in 9 months, less time than the full year originally planned. After the initial migration, the monolith was then tweaked and tuned to situate better in the cloud, adding features like autoscaling and auto-fixing bad nodes.
Meanwhile, other stacks were also being migrated. While each team created its own journey, the teams were not completely on their own. Etsy used a cross-team architecture advisory group to share broader context, and to help pattern match across the company. For example, the search stack moved onto GKE as part of the cloud, which took longer than the lift and shift operation for the monolith. Another example is the data lake migration. Etsy had an on-prem Vertica cluster, which they moved to Big Query, changing everything about it in the process.
Not surprising to Etsy, after the cloud migration the optimization for the cloud didn’t stop. Each team continued to look for opportunities to utilize the cloud to its full extent. With the help of the architecture advisory group, they looked at things such as: how to reduce the amount of custom code by moving to industry-standard tools, how to improve cost efficiency and how to improve feedback loops.
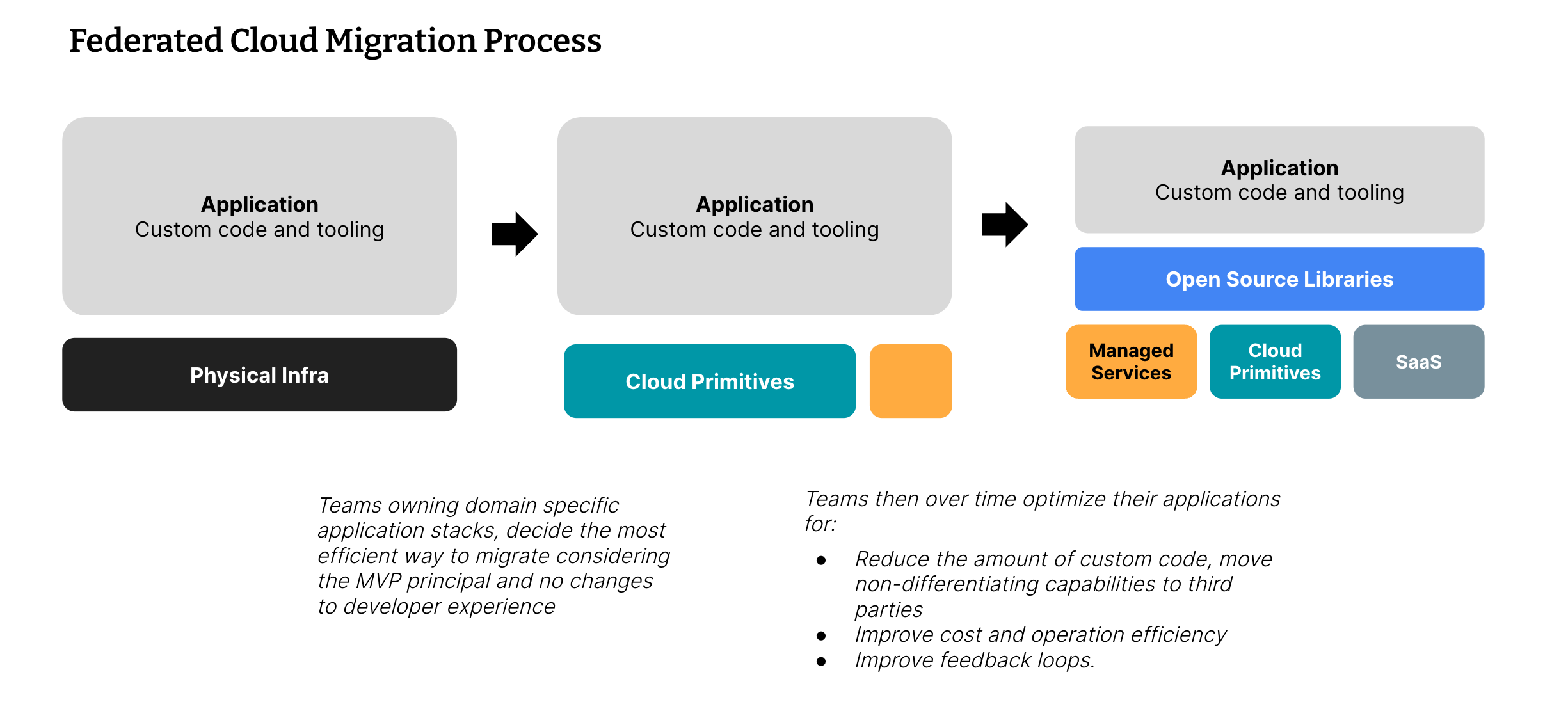
Figure 1: Federated cloud migration
As an example, let’s look at the journey of two teams, observability and ML infra:
The challenges of observing everything
Etsy is famous for measuring everything, “If it moves, we track it.” Operational metrics - traces, metrics and logs - are used by the full company to create value. Product managers and data analysts leverage the data for planning and proving the predicted value of an idea. Product teams use it to support the uptime and performance of their individual areas of responsibility.
With Etsy’s commitment to hyper-observability, the amount of data being analyzed isn’t small. Observability is self-service; each team gets to decide what it wants to measure. They use 80M metric series, covering the site and supporting infrastructure. This will create 20 TB of logs a day.
When Etsy originally developed this strategy there weren’t a lot of tools and services on the market that could handle their demanding requirements. In many cases, they ended up having to build their own tools. An example is StatsD, a stats aggregation tool, now open-sourced and used throughout the industry. Over time the DevOps movement had exploded, and the industry had caught up. A lot of innovative observability tools such as Prometheus appeared. With the cloud migration, Etsy could assess the market and leverage third-party tools to reduce operational cost.
The observability stack was the last to move over due to its complex nature. It required a rebuild, rather than a lift and shift. They had relied on large servers, whereas to efficiently use the cloud it should use many smaller servers and easily scale horizontally. They moved large parts of the stack onto managed services and third party SaaS products. An example of this was introducing Lightstep, which they could use to outsource the tracing processing. It was still necessary to do some amount of processing in-house to handle the unique scenarios that Etsy relies on.
Migration to the cloud-enabled a better ML platform
A big source of innovation at Etsy is the way they utilize their Machine learning.
Etsy leverages machine learning (ML) to create personalized experiences for our millions of buyers around the world with state-of-the-art search, ads, and recommendations. The ML Platform team at Etsy supports our machine learning experiments by developing and maintaining the technical infrastructure that Etsy’s ML practitioners rely on to prototype, train, and deploy ML models at scale.
The move to the cloud enabled Etsy to build a new ML platform based on managed services that both reduces operational costs and improves the time from idea generation to production deployment.
Because their resources were in the cloud, they could now rely on cloud capabilities. They used Dataflow for ETL and Vertex AI for training their models. As they saw success with these tools, they made sure to design the platform so that it was extensible to other tools. To make it widely accessible they adopted industry-standard tools such as TensorFlow and Kubernetes. Etsy’s productivity in developing and testing ML leapfrogged their prior performance. As Rob and Kyle put it, “We’re estimating a ~50% reduction in the time it takes to go from idea to live ML experiment.”
This performance growth wasn’t without its challenges however. As the scale of data grew, so too did the importance of high-performing code. With low-performing code, the customer experience could be impacted, and so the team had to produce a system which was highly optimized. “Seemingly small inefficiencies such as non-vectorized code can result in a massive performance degradation, and in some cases we’ve seen that optimizing a single tensor flow transform function can reduce the model runtime from 200ms to 4ms.” In numeric terms, that’s an improvement of two orders of magnitude, but in business terms, this is a change in performance easily perceived by the customer.
What were the challenges of the cloud?
Etsy had to operate its own infrastructure, and a lot of the platform teams' skills were in systems operation. Moving the cloud allowed teams to use a higher abstraction, managed by infrastructure as code. They changed their infrastructure hiring to look for software engineering skills. It caused friction with the existing team; some people were very excited but others were apprehensive about the new approach.
While the cloud certainly reduced the number of things they had to manage and allowed for simpler planning, it didn’t fully get them away from capacity planning. The cloud services still run on servers with CPUs and Disks, and in some situations, there is right-sizing for future load that has to be done. Going forward, as on-demand cloud services improve, Etsy is hopeful they can reduce this capacity planning.
The stress test of the pandemic
Etsy had always been data center based, which had kept them constrained in some ways. Because they'd been so heavily invested in their data center presence, they hadn't been taking advantage of new offerings cloud vendors had developed. For example, their data center setup lacked robust APIs to manage provisioning and capacity.
When Mike Fisher came onboard, Etsy then began their cloud migration journey. This set them up for success for the future, since the migration was basically finished at the start of the pandemic. There were a few ways this manifested: they had no capacity crunch, although traffic exploded 2-3X overnight, as events had increased from 1 billion to 6 billion.
And there were specific examples of ways the cloud gave them agility during the pandemic. For example, the cloud enabled efforts to close the “semantic gap”, ensuring searches for “masks” surfaced cloth masks not face masks of the cosmetic or costume variety. This was possible because Google Cloud enabled Etsy to implement more sophisticated machine learning and the agility to retrain algorithms in real time. Another example was their database management changed from the datacenter to the cloud. Specifically, around backups, Etsy's DR posture improved in the cloud, since they leveraged block storage snapshotting as a way of restoring databases. This enabled them to do fast restores, have confidence and be able to test them quickly, unlike the older method, where a restore would take several hours and not be perfectly scalable.
Etsy performs extensive load and performance testing. They use chaos engineering techniques, having a ‘scale day’ that stresses the systems at max capacity. After the pandemic the increased load was no longer a spike, it was now the daily average. The load testing architecture and techniques needed to be just as scalable as any other system in order to handle the growth.
Continually Improving the platform
One of Etsy’s next focus areas is to create “paved roads” for engineers. A set of suggested approaches and machinery to reduce friction when launching and developing services. During the initial four years of the cloud migration, they decided to take a very federated strategy. They took the “let 1000 flowers bloom” approach as described by Peter Seibel in his article on engineering effectiveness at Twitter. The systems had never existed in the cloud before. They did not know what the payoffs would be, and wanted to maximize the chances of discovering value in the cloud.
As a result, some product teams are reinventing the wheel because Etsy doesn’t have existing implementation patterns and services. Now that they have more experience operating in the cloud, platform teams know where the gaps are and can see where tooling is needed.
To determine if the investments are paying off. Etsy is tracking various measures. For example, they monitor trends in SLI/SLOs related to reliability, debuggability and availability of the systems. One other key metric is Time to Productive – the time it takes for a new engineer to be set up with their environments and make the first change. What exactly that means changes by domain; for example it might be the first website push or the first data pipeline working in the big data platform. Something that used to take 2 hours now takes 20 minutes.
They combine these quantitative metrics with regularly measuring engineering satisfaction, using a form of an NPS survey to assess how engineers enjoy working in their respective engineering environments, and give an opportunity to point out problems and suggest improvements. Another interesting stat is that the infrastructure has expanded to use 10x the number of nodes but only requires 2x the number of people to manage them.
Measuring Cost and Carbon Consumption
Etsy continues to embrace measuring everything. Moving to the cloud made it easier for teams to identify and track their operational costs than it had been in the datacenters. Etsy built tools on top of Google Cloud to provide dashboards which give insight into spending, in order to help teams understand which features were causing costs to rise. The dashboards included rich contextual information to help them make optimization decisions, measured against their understanding of what ideal efficiency should be.
A very important company pillar is sustainability. Etsy reports their energy consumption in their quarterly SEC filings, and have made commitments to reduce it. They had been measuring energy consumption in the data center, but trying to do this in the cloud was initially more difficult. A team at Etsy researched and created Cloud Jewels, an energy estimation tool, which they open-sourced.
We’ve been unable to measure our progress against one of our key impact goals for 2025 -- to reduce our energy intensity by 25%. Cloud providers generally do not disclose to customers how much energy their services consume. To make up for this lack of data, we created a set of conversion factors called Cloud Jewels to help us roughly convert our cloud usage information (like Google Cloud usage data) into approximate energy used. We’re proud that our work and methodology have been leveraged by Google and AWS to build into their own models and tools.
-- Emily Sommer (Etsy sustainability architect)
These metrics have recently been added to their product dashboard, allowing product managers and engineers to find opportunities to reduce energy consumption and spot whether a new feature has had any effect. Thoughtworks, who has a similar sustainability mission, also created an open-source tool called the Cloud Carbon Footprint, which was inspired by initial research into Cloud Jewels, and further developed by an internal Thoughtworks team.
Acknowledgements
Thanks to Martin Fowler, Christopher Hastings, and Melissa Newman for their writing help, and to Dale Peakskill, Kyle Gallatin, Emily Sommer and Rob Miles, for sharing the stories of their scaling work.
Special thanks to Mike Fisher for being so open about Etsy’s scaling journey.
Significant Revisions
29 November 2022: Published rest of the article
22 November 2022: Published sections on observability and ML platform
17 November 2022: Published first installment