
Organizing Presentation Logic
There are several ways to split up the logic of the presentation.
11 July 2006

This is part of the Further Enterprise Application Architecture development writing that I was doing in the mid 2000’s. Sadly too many other things have claimed my attention since, so I haven’t had time to work on them further, nor do I see much time in the foreseeable future. As such this material is very much in draft form and I won’t be doing any corrections or updates until I’m able to find time to work on it again.
One of the most useful things you can do when designing any presentation layer is to enforce Separated Presentation. Once you've done this, the next step is to think about how the presentation logic itself is going to be organized. For a simple window, a single class may well suffice. But more complex logic leads to a wider range of breakdowns.
The most common approach is to design one class for each window in the application. This class usually inherits from the GUI library's window class and includes all the code needed to handle that window. If a window contains a complex panel, you may have a separate class for that panel - leading to a composite structure. I'm not going to go into this kind of composite structuring, since that's pretty straightforward, instead I'll focus more on ways of organizing the basic behavior within a single window.
The Album List Running Example
For much of the discussion and examples here, I'm going to use a single example screen to discuss the issues that come up (Figure 1). The window shows information about music recordings. For each album it displays the artist, title, whether it's a classical recording, and if it is classical: the composer. I chose the example to include some elements of presentation logic.
{kind=link}
- The choice in the list selection determines which album's data is shown in the fields.
- The window title is derived from the title of the currently displayed album.
- The composer field is only enabled when the classical check box is checked.
- The apply and cancel buttons are only enabled when data has been edited.
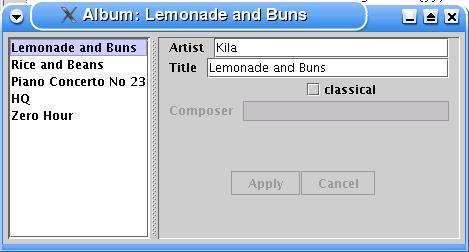
Figure 1: A simple album information window
Separting presentation logic from the View
Although putting all the presentation logic in an Autonomous View is both common and workable, it does come with disadvantages. The most common disadvantage talked about these days with Autonomous View is to do with testing. Testing a presentation through a GUI window is often awkward, and in some cases impossible. You have to build some kind of UI driver that will drive the GUI. Some people use GUI tools that simulate raw mouse and keyboard events - but these tools usually create brittle tests that give false positives whenever minor changes occur to the presentation. More detailed tools address the UI controls more directly, these are less brittle but still troublesome. They also depend of the GUI framework having enough support for direct control access via an API - and not all do.
As a result many advocates of programmer based testing advocate a humble dialog (also known as an ultra-thin GUI). The core idea here is to make the class that contains the UI controls as small and stupid as possible by moving all the logic into other presentation layer classes. This GUI control class is usually referred to as the view, for reasons I'll get into shortly. You can then run your tests against the intelligent classes without needing to use any GUI controls, stubbing the humble view if necessary. Since the view is very stupid, there's little that can go wrong and you can find most bugs by working on the intelligent classes. A term I like to use for this style of testing is subcutaneous testing, since the tests operate just under the skin of the application.
Although subcutaneous testing is the primary reason these days for splitting a presentation class, there are a couple of other reasons why such split is worth considering. The intelligent classes can be made independent of several aspects of the view, such as the choice of controls, the layout of the controls, and potentially even the precise UI framework itself. This allows you to support multiple different views with the same logical behavior. Although this can be useful, supporting multiple 'skins' for a application, you can only do a limited set of variations by just replacing a humble view.
In some ways separating the presentation logic can make it easier to program the presentation. It allows you to ignore details of the view layout while you are writing your behavior, effectively giving you a more comfortable api to the view's controls. Stacked against this, however, is the fact that separating the presentation logic does result in extra machinery to support the separation (the nature of which varies depending on which pattern you use.) As a result there's a rational argument in both directions, saying separation either simplifies or adds complexity to a presentation.
There is a historical precedent for doing this split - it was part of the Model View Controller (MVC). As I discussed in [P of EAA], the MVC approach did two separations. The most important separation was Separated Presentation - separating the model from the view/controller. The other separation, that of the view and controller, was not popular in rich client GUI frameworks, although it did have a resurgance with web based user interfaces. In MVC the view was a simple display of information in the model and the controller handled the various user input events. This doesn't work well with most GUI frameworks because they are designed so that the UI controls both display and receive the user input events.
To create a humble view, the design must move all behavior out of the view - both handling of user events and any display logic of domain information. There are two main ways of doing this. First is the the Model-View-Presenter style where behavior is moved into a presenter, which you can think of as a form of controller. The presenter handles user events and also has some role in updating the view. Supervising Controller and Passive View are two styles of this approach. Supervising Controller puts simple view logic in the view, while Passive View puts all view logic in the controller. The alternative style is Presentation Model which creates a form of model that captures all the data and behavior so that the view only needs a simple synchronization.
In both styles the view is the initial handler of user events but then immediately hands off control to the controller.
All three of these patterns, by introducing an extra class, produce a arguably more complex design. Splitting a class that does too much into separate classes to fulfil each responsibility is a good practice - but the question is whether an Autonomous View is too complex. Certainly the other patterns provide other testing options and the ability to support multiple views. If you don't need the multiple views and are happy with testing through the view then Autonomous View may well be fine, particularly if the window isn't too complex.
The choice between Presentation Model, Supervising Controller and Passive View is more arbitrary - it really comes down to how easy it is to do the pattern in your GUI environment and on your own personal tastes.
Whenever we use terms from MVC there's inevitably the question of what is the model. In classic Smalltalk MVC the model was a Domain Model. In general the model in an MVC discussion these days means the interface to the domain layer; which could be a classic domain model, or a Service Layer, Transaction Scripts, Table Modules or any other representation of the domain. Indeed if there is no separate domain layer the model could well be the interface to a database.
Screens, Layers, and Data
Most enterprise applications involve editing data. This data is usually copied between several layers of the application, and probably between multiple users using the same system. Much of the behavior of an enterprise application depends on how the changes of this data are coordinated and how the data is synchronized between the layers. There's no generally accepted terminology for how to think about this, for the purpose of this book I'm going to impose the following.
Layers of Data
The first issue to think about is the different copies of the data in different layers. Thinking about this in physical terms there's the usually difference between data in memory and data in a database or files. You can think of this as the difference between transient and persistant data. However I find it's usually a bit more than this. Even data in memory is often in two places. Often you'll find a difference between data on a screen and data in some form of in memory store that backs a screen. This could be in a Record Set retrieved from a database (but not yet committed back to the database), or in a Domain Model.
Consider working on a document in in a word processor. The document is on disk and you've opened the document in the word processor and edited the text of the document. This yields different text in memory than from on disk. Now open a dialog box to change the formatting for some of the text. Often you can change the formatting in the dialog box but it doesn't change the underlying text until you hit an apply button. The formatting data in the dialog box is in-memory data, but it's different data to that in the main in-memory document.
The terminology I shall use in this book is screen state, session state, and record state. Screen State is data displayed on a user interface. Session State is data that the user is currently working on. Session state is seen by the user as somewhat temporary, they usually have the ability to save or discard their work. Record State refers to more permanent data, data that's expected to sit around between the sessions.
Session state is primarily acted on in-memory, but is often stored to disk. Modern word processors often save rescue files to avoid losing work due to power loss or a system crash. An enterprise application can save session state in a checkpoint file locally or the server may save state to disk between requests.
In an enterprise application a particular distinction between session and record state is that record state is shared between the multiple users of a system, while the session state is private state visible only to user working on it. So not just is the user deciding to save changes to a more permanent form, they are also deciding to share it with their co-workers. Session state often correlates with a single business transaction, although it often spans multiple system transactions, a situation that often requires offline concurrency.
Not all applications have session state. Some just have screen state and record state - any change to the data when saved goes directly to the record state. In these cases you may not have any session state at all, or any changes are written immediatly to record state so the session state is always in lock step with the record state. Not having session state greatly simplifies and application as you then don't have to worry about managing the session state. It's even preferred by users in many applications since the user never needs to worry about losing work. However leaving out session state isn't all strawberries. The user looses the ability to play around with a scenario in working state and then discarding it if they don't like it. It also stops people working independently on a multi-user application.
You can get extra layers of state too. An example of this is when session state is stored on both a client tier and a server tier. These states can change independently, although there are usually fairly restricive rules about how they syncrhonize which makes managing them much simpler.
An example of extra layers would be how a developer works on a team. In this case the record state is the state of the shared source code repository. The working copy on the developer's local machine is a form of session state, sitting on the disk. In this case it's somewhat transient itself. There are then other representations in the IDE. In a modern IDE that holds and constantly updates an syntax tree in memory you have that, plus the text shown on the screen. In this case there more than three layers, but it's still useful to think about what the developer sees on the screen, his private session data, and the shared permenant data. To reason about effectively I would name each set of data and talk about them as separate layers. Particular applications will always have their own set, for my discussion I'll focus on the common triad of screen, session, and record state.
Most of the time a user works in a single session at one time. On occasion a user will operate in multiple sessions at once. This often causes confusion because changes in one session won't show up in another session until both are synchronized with record state. You can get around this by synchronizing the two sessions, but it's usually messy.
These multiple states often correspond to the various layers of an enterprise application. In an ideal application that uses presentation, domain, and data source layers you'll have domain logic only operating on session state. In practice this distinction gets muddied, usually for bad reasons but sometimes for a good reason. In an application where the domain layer is on a separate process to the presentation you may want some domain logic running in the presentation process to make the application properly responsive. Such logic may involing copying some session state from the main domain process, or you may have to run domain logic against the data in the presentation's controls. Similarly if you need to operate on large amounts of data you may need to embed domain logic into a database through something like stored procedures. Such logic operates on record state. However most of the time you want domain logic to operate on session state.
Synchronizing Between Layers
Synchronizing data between these different contexts is an important part of building an application. When you're working on a user interface you can synchronize the screen state to two different depths: the session state or the record state. If you synchronize to session state you'll need some control that allows the user to save the session state to the record state.
Synchronization can occur at various frequencies, I find the following three useful. Key Synchronization means you synchronize on each key press or mouse click. Field synchonization means you synchonize when you finish editing a field. Screen synchronization means you synchronize when you some special buttons in the UI (usually labelled 'apply', 'OK', 'cancel', or 'submit') when you are done with a screenful of information.
Once you need to synchronize, the next question is how much do you synchronize. When you're looking at synchronizing screen data with session data then I see two main schemes. Coarse-grained synchronization implies that whenever you change anything on the UI, the entire UI is synchronized; so changing the artist field means synchronizing the entire window even though nothing else needs to change. Fine-grained synchronization means only changing the fields that really need updating. So changing the title field would involve synchronizing the title field, window title, and list box - but nothing else.
Synchronizing between the session data and record data usually uses a different approach. Session data isn't usually used by multiple people simultaneously, so you don't have to worry about concurrency issues. Syncrhonizing between session and record data usually occurs with screen synchronization and usually takes longer. As a result you do such things as mark data elements as dirty or use a Unit of Work.
All of these aspects trade off with each other in both the internal design and the interaction design of the UI. The most obvious trade-offs occur between the frequency and depth of synchronization. Using key synchronization down to record state would lead to unnacceptable performance, amongst other ills. As a result most of the time I see screen synchronization used at that depth. Indeed screen synchronization is also the most common at session depth too. It's usually the easiest to do and many applications work that way so users are used to it. However it's also quite common that the interaction design really needs field synchronization. Field synchronization is pretty easy if the domain logic is in the same process as the presentation, it's rather more awkward to get good performance if it's in a different process. So for the domain layer, screen synchronization is a reasonable default, but expect to do field synchronization fairly often.
Key synchronization seems to be rarer, but is pretty easy to do if the domain is in the same process.
While timing choices vary with depth and application design, I'm almost always in favor of coarse-grained synchronization between screen and session states. Many people shy away from coarse-grained synchronization because they're concerned with the performance implications. But fine-grained synchronization is a bear to maintain since there's lots of code with frequent duplication. Bugs in all this are hard to spot and thus fix. Most of the time coarse-grained synchronization is quite performant enough, so my advice is to always use it first. If you do run into performance issues, and you've profiled to check that it really is the synchronization, then you must introduce a little fine-grained synchronization to fix it. At that point do the minimum you need to do to deal with the performance issue.
This need for synchronization is such a common one, that it's inevitable that people develop frameworks to try to handle it. One that gets a lot of attention is the data binding framework in .NET, which autmatically synchronizes screen and session state. Data binding has many nice qualities and in theory should be able handle synchronization well. So far (up to version 1.0) I've found that it works well for simple cases but breaks down in moderately complex ones. Projects I've talked who started with data binding ended up dropping after a while because there weren't enough ways to control how the binding was working. As a result I would advise treating it warily unless your needs are very simple. However do re-evaluate it in later versions - I could easily see this turning into a very effective solution to synchronization issues.
Synchronization and Multiple Screens
One part of synchronization is about synchronizing between the layers of state, another part is dealing with synchronizing between multiple strands of the same layer. You'll often find mutliple sessions on top of a single record state, and multiple screens on top of each session. Each of these is a separate context, and you have to think about how changes in one context are propagated into other contexts.
Since I'm talking about presentations here, I'm not going to say much about synchronizing multiple sessions. In any case that's a better understood and relatively straightforward topic. Most of the time sessions are isolated from each other and only syncrhonize with record state. They use transactions or some form of offline concurrency control to do that.
Presentations are more complex because users expect less isolation and more rapid synchronization.
How best to synchronize multiple screens depends very much on the way screens are organized and on how the flow between screens is structured. To look at it from two extremes, we can think about contrasting wizards with a completely non-modal interface such as a file system explorer.
With a wizard user-interface, the system guides the user through a very controlled flow of screens. At any time only one screen is visible and usually the user can only go backwards or forwards from each screen. In this situation the designer of the screen knows exactly what data is displayed and exactly when screens are opened and closed.
With a file system explorer the user can move around between screens at will. More importantly the user can open up multiple explorer windows showing the same files. If a user changes the name of a folder in one window, other windows should be updated too. The programmer of the UI is never really sure when windows will be opened and whether the same data is displayed in multiple windows or not.
These two extremes suggest two different ways of coordinating information between screens. With Flow Synchronization each screen decides when to synchronize its screen state with any underlying session state, based on the flow of the application. So with a wizard, the screens would typically syncrhonize when moving from one screen to another; writing out the old screen and reading in data for the new one. Flow Synchronization works best when the flow between screens is simple and there are clear points at which you can save and load data from screen state into session state.
For a file explorer Flow Synchronization would be difficult. One screen can never really tell whether another screen has changed the underlying data. In this case the screens need to be unaware of each other, and synchronize whenever the underlying data changes. With Observer Synchronization the underlying screen state acts as the master source of the data. Whenever it changes, the screens that display are notified and can update their screen state, usually using the Observer pattern. In this form Observer Synchronization is a fundamental part of the Model View Controller style.
The nice thing about Observer Synchronization is that all the screens are always completely independent of each other, both in that they don't need to know about each other to synchronize and that they don't need to tell each other about synchronization events. This makes it easy to have very ad-hoc and complex flows in the application. The downside of Observer Synchronization is that it relies on using Observer and that introduces some implicit behavior that can get very tricky if you let it go out of control.
On the whole, however, Observer Synchronization is the dominant choice for complex UIs. Flow Synchronization is really only usuable if the application flow is very simple: usually one active screen at a time and simple flows between screens. Even then, once you are used to Observer Synchronization you may prefer to use it even for these simple cases.
Observer Gotchas
Many interactions in a rich client presentation make use of the Observer pattern. Observer is a useful pattern, but it comes with some important issues that you need to be aware of.
The great strength, and weakness, of observer is that control passes from the subject to the observer implicitly. You can't tell by reading code that an observer is going to fire, the only way you can see what's happening is to use a debugger. As a result of a complex chain of observers can be a nightmare to figure out, change, or debug as actions trigger other actions with little indication why. As a result I strongly recommend that you use observers only in a very simple manner.
- Don't have chains of objects observing other objects, observing other objects. One layer of observer relationships is best (unless you use an Event Aggregator
- Don't have observer relationships between objects in the same layer. Domain objects shouldn't observe other domain objects, presentations should not observer other presentations. Observers are best use across the layer boundary, the classic use is for presnetations to observer the domain.
Another issue for observers lies in memory management. Assume we have some screens observing some domain objects. Once we close a screen we want it to be deleted, but the domain objects actually carry a reference to the screen though the observer relationship. In a memory-managed environment long lived domain objects can hold onto a lot of zombie screens, resulting in a significant memory leak. So it's important for observers to de-register from their subjects when you want them to be deleted.
A similar issue often occurs when you want to delete the domain object. If you rely on breaking all the links between the domain objects this may not be enough since screens may be observing the domain. In practice this turns out be a problem less frequently as the screen departs and the domain objects lifetime are usually controlled through the data source layer. But in general it's worth keeping in mind that observer reltionships often hang around forgotton and a frequent cause of zombies. Using an Event Aggregator will often simplify these relationships - while not a cure it can make life easier.
I'd particularly like to thank my colleague Xiao Guo for catalyzing much of the thinking in this chapter with his analysis of his experiences in window navigation and data synchronization. Patrik Nordwall pointed out the problem with observers and memory leaks.
Significant Revisions
11 July 2006: Initial update to handle split in MVP styles
20 November 2004: Added flow synchronization discussion.
04 August 2004: Added material on screens, layers, and data inspired by conversations with Xiao Guo.
19 July 2004: First public release. Mostly on Presentaton Model and MVP comparison.
15 May 2004: Internal release to TW