
Function Length
30 November 2016

During my career, I've heard many arguments about how long a function should be. This is a proxy for the more important question - when should we enclose code in its own function? Some of these guidelines were based on length, such as functions should be no larger than fit on a screen 1. Some were based on reuse - any code used more than once should be put in its own function, but code only used once should be left inline. The argument that makes most sense to me, however, is the separation between intention and implementation. If you have to spend effort into looking at a fragment of code to figure out what it's doing, then you should extract it into a function and name the function after that “what”. That way when you read it again, the purpose of the function leaps right out at you, and most of the time you won't need to care about how the function fulfills its purpose - which is the body of the function.
1: Or in my first programming job: two pages of line printer paper - around 130 lines of Fortran IV
Once I accepted this principle, I developed a habit of writing very small functions - typically only a few lines long 2. Any function more than half-a-dozen lines of code starts to smell to me, and it's not unusual for me to have functions that are a single line of code 3. The fact that size isn't important was brought home to me by an example that Kent Beck showed me from the original Smalltalk system. Smalltalk in those days ran on black-and-white systems. If you wanted to highlight some text or graphics, you would reverse the video. Smalltalk's graphics class had a method for this called 'highlight', whose implementation was just a call to the method 'reverse' 4. The name of the method was longer than its implementation - but that didn't matter because there was a big distance between the intention of the code and its implementation.
2: Many languages allow you to use functions to contain other functions. This is often used as a scope reduction mechanism, such as using the Function as Object pattern to implement a class. Such functions are naturally much larger.
3:
Recently I got curious about function length in the toolchain that builds this website. It's mostly Ruby and runs to about 15 KLOC. Here's a cumulative frequency plot for the method body lengths
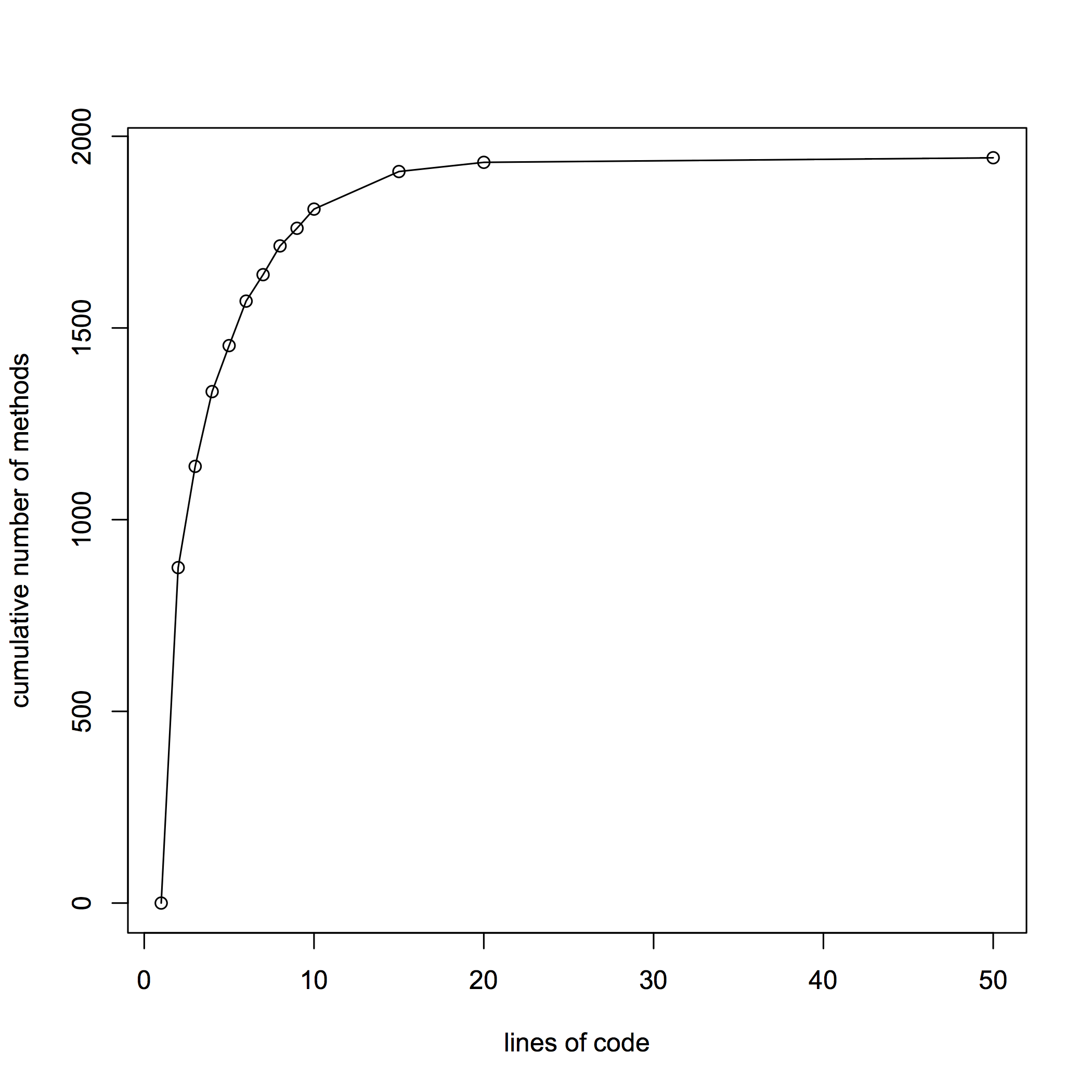
As you see there's lots of small methods there - half of the methods in my
codebase are two lines or less. (lines here are non-comment, non-blank, and
excluding the def and end lines.)
Here's the data in a crude tabular form (I'm feeling too lazy to turn it into proper HTML tables).
lines.freq lines.cumfreq lines.cumrelfreq
[1,2) 875 875 0.4498715
[2,3) 264 1139 0.5856041
[3,4) 195 1334 0.6858612
[4,5) 120 1454 0.7475578
[5,6) 116 1570 0.8071979
[6,7) 69 1639 0.8426735
[7,8) 75 1714 0.8812339
[8,9) 46 1760 0.9048843
[9,10) 50 1810 0.9305913
[10,15) 98 1908 0.9809769
[15,20) 24 1932 0.9933162
[20,50) 12 1944 0.9994859
4: The example is in Kent's excellent Smalltalk Best Practice Patterns in Intention Revealing Message
Some people are concerned about short functions because they are worried about the
performance cost of a function call. When I was young, that was occasionally a factor,
but that's very rare now. Optimizing compilers often work better with shorter functions
which can be cached more easily. As ever, the general guidelines on performance
optimization are what counts. Sometimes inlining the function later is what you'll
need to do, but often smaller functions suggest other ways to speed things up. I remember
people objecting to having an isEmpty method for a list when the
common idiom is to use aList.length == 0. But here using the
intention-revealing name on a function may also support better performance if it's
faster to figure out if a collection is empty than to determine its length.
Small functions like this only work if the names are good, so you need to pay good attention to naming. This takes practice, but once you get good at it, this approach can make code remarkably self-documenting. Larger scale functions can read like a story, and the reader can choose which functions to dive into for more detail as she needs it.
Acknowledgements
Brandon Byars, Karthik Krishnan, Kevin Yeung, Luciano Ramalho, Pat Kua, Rebecca Parsons, Serge Gebhardt, Srikanth Venugopalan, and Steven Lowe discussed drafts of this post on our internal mailing list.
Christian Pekeler reminded me that nested functions don't fit my sizing observations.
Notes
1: Or in my first programming job: two pages of line printer paper - around 130 lines of Fortran IV
2: Many languages allow you to use functions to contain other functions. This is often used as a scope reduction mechanism, such as using the Function as Object pattern to implement a class. Such functions are naturally much larger.
3: Length of my functions
Recently I got curious about function length in the toolchain that builds this website. It's mostly Ruby and runs to about 15 KLOC. Here's a cumulative frequency plot for the method body lengths
As you see there's lots of small methods there - half of the methods in my
codebase are two lines or less. (lines here are non-comment, non-blank, and
excluding the def and end lines.)
Here's the data in a crude tabular form (I'm feeling too lazy to turn it into proper HTML tables).
lines.freq lines.cumfreq lines.cumrelfreq
[1,2) 875 875 0.4498715
[2,3) 264 1139 0.5856041
[3,4) 195 1334 0.6858612
[4,5) 120 1454 0.7475578
[5,6) 116 1570 0.8071979
[6,7) 69 1639 0.8426735
[7,8) 75 1714 0.8812339
[8,9) 46 1760 0.9048843
[9,10) 50 1810 0.9305913
[10,15) 98 1908 0.9809769
[15,20) 24 1932 0.9933162
[20,50) 12 1944 0.9994859
4: The example is in Kent's excellent Smalltalk Best Practice Patterns in Intention Revealing Message